Учебник "Маркетинговые исследования"
Соколова М.И., Гречков В.Ю.
Содержание
- Глава 1: Маркетинговые исследования
- Глава 2: Некоторые основные положения математической статистики
- Глава 3: Использование программы статистической обработки SPSS (v8.0) при анализе результатов маркетинговых исследований
- Приложение 1: Опросный лист (пример)
- Приложение 2: Терминология, используемая в программе SPSS
Глава 3. Использование программы статистической обработки SPSS (v 8.0) при анализе результатов маркетинговых исследований
Для работы со статистической компьютерной программой SPSS прежде всего необходимо иметь результаты проведенного опроса (заполненные опросные листы). С образцом, представляющим собой простой пример варианта опросного листа, можно ознакомиться в Приложении 1).
По выбранным отдельным вопросам, либо по всем вопросам опросного листа, необходимо выявить статистически значимые закономерности; определить статистические распределения вариантов ответов; оценить близость к нормальному закону распределения. Программа SPSS позволяет выводить на печать необходимые таблицы, строить графики, диаграммы и/или гистограммы.
Изучив полученные данные и сделав окончательные выводы, требуется сформировать итоговый отчет с подробным анализом результатов маркетингового исследования.
3.1. Ввод данных и определение типов переменных.
Редактирование данных.
После загрузки программы SPSS на экран выводится окно редактора данных (сетка, аналогичная сетке программы Excel) с панелью инструментов и пунктами меню (рис. 3.1).
Для дальнейшей работы необходимо либо загрузить уже имеющиеся данные из файла с расширением *.sav, либо ввести новые данные и, разумеется, сохранить их в файле ИМЯ.sav . Для ввода данных и определения переменных используются пункты основного меню Data – Define Variable (рис. 3.2).
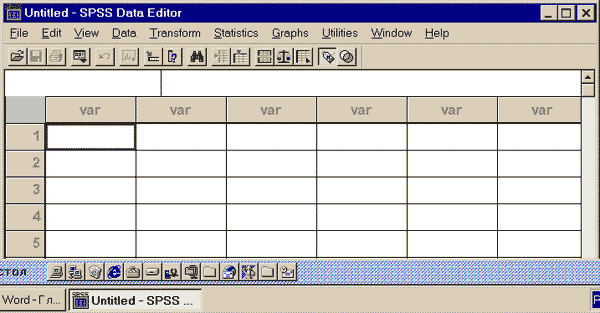
Рис. 3.1 Окно редактора данных программы SPSS
При вводе каждой переменной необходимо определить:
- имя переменной;
- тип переменной (Type);
- пропущенные значения (Missing Values);
- метку переменной (Labels) – для удобства работы метку
можно записать и на русском языке;
- расположение переменных в таблице (Column Format).
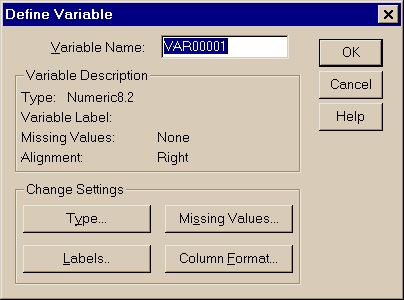
Рис. 3.2. Окно ввода данных
Рекомендуется определить также метки значений переменной – Value Labels, например: “0” – нет ответа, “1” – да, “2” - нет и т.п.
Для имени переменной должны выполняться следующие правила:
- имя должно начинаться с буквы, остальные символы могут быть любые;
- имя не может оканчиваться точкой или символом подчеркивания;
- длина имени не может превышать восьми знаков;
- в именах не могут использоваться пробелы или специальные символы: !, ?, *) и т.п.;
- имена переменных нечувствительны к регистру.
Возможными типами переменной могут быть: числовой, с точкой, с запятой, научное представление, дата, денежное представление (доллар), денежное представление (произвольная валюта) и строковый. Форматы произвольной валюты определяются в разделе Currency в диалоговом окне Options, доступном из пункта меню Edit.
Метка может быть приписана каждому значению переменной. Это очень удобно, поскольку длина имени не может превышать 8 символов, а метки переменных могут быть длиной до 256 символов, и эти описывающие переменные метки отображаются при выводе.
Пользователь имеет возможность определить некоторые значения данных как пропущенные. Это очень часто оказывается полезным при выяснении причин отсутствия информации. Например, исследователь хотел бы отделить данные, пропущенные потому, что респондент отказался отвечать, от данных, пропущенных потому, что данный вопрос не имел отношения к респонденту. Значения данных, обозначенные как пользовательские пропущенные, специально помечаются для того, чтобы исключить их из большинства вычислений.
Диалоговое окно Templates позволяет создавать шаблоны определения переменных (рис. 3.3) и применять из при вводе.
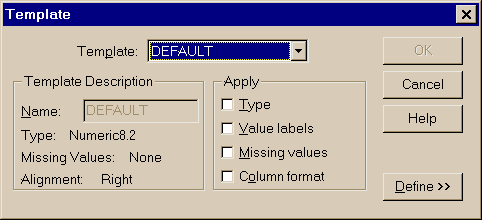
Рис. 3.3. Диалоговое окно определения шаблона переменной.
Данные вводятся в любом порядке - по наблюдениям или по переменным, для выбранных областей или для отдельных ячеек. Активная ячейка выделяется жирной рамкой. Значения данных не записываются, пока пользователь не нажмет на Enter или не выберет другую ячейку. Для ввода данных типа, отличного от простого числового, необходимо сначала определить тип переменной.
После ввода данных их необходимо обязательно сохранить на жестком диске в файле с оригинальным именем и расширением *.sav : File – Save As…
Введенные данные можно редактировать с помощью Редактора Данных, который позволяет:
- Изменять значения данных.
- Вырезать, копировать, вставлять значения данных
- Добавлять и удалять наблюдения и\или переменные
- Изменять порядок или определения переменных
- Проводить поиск значений данных, переходить к определенному наблюдению.

Рис. 3.4. Опции редактора данных (пункт меню Edit)
В программе SPSS имеются также средства для работы с файлами данных в различных форматах. В частности, программа обеспечивает доступ к электронным таблицам, созданным в Lotus 1-2-3 или Excel, к файлам баз данных, созданным в системе dBASE и различных форматах SQL, к текстовым файлам данных.
3.2. Возможности SPSS по использованию методов
описательной статистики
Для анализа результатов маркетинговых исследований может быть использовано множество методов математической статистики, реализованных в программе SPSS. В данном учебном пособии рассмотрены основы работы лишь с некоторыми основными методами.
Как уже говорилось в Главе 2, к методам описательной статистики относится, в частности, построение частотных таблиц. Выбираем пункты меню:
Statistics – Summarize – Frequencies – выбор дискретной переменной (переменных).
В диалоговом окне процедуры Frequencies (Частоты) исследователь может (рис. 3.5):
- нажав кнопку Statistics, задать вычисление максимального, минимального и среднего значения, моды, медианы, среднеквадратического отклонения для количественных переменных;
- кнопкой Charts задать вид графиков – столбиковая или круговая диаграммы, гистограмма;
- кнопкой Format задать порядок, в котором будут выводиться результаты.
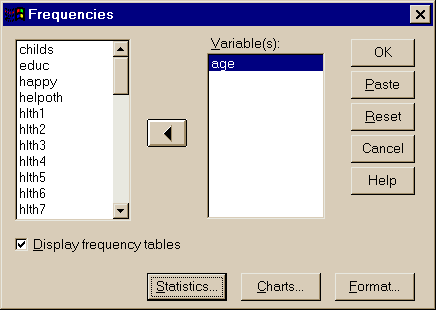
Рис. 3.5. Диалоговое окно процедуры Частоты.
Для непрерывных переменных может использоваться обобщающая статистика:
Statistics – Summarize – Descriptives.
Процедура Descriptives осуществляет вывод одномерных статистик для нескольких переменных в одной таблице, а также вычисляет нормированные значения переменных. Переменные могут быть упорядочены по величине их средних значений (в порядке возрастания или убывания), по алфавиту или в порядке, в котором пользователь выбирает переменные (используется по умолчанию).
Например, если каждое наблюдение в анализируемых данных содержит итоги дневных объемов продаж для одного из дистрибьюторов компании в течение нескольких месяцев, то эта процедура поможет рассчитать средний дневной объем продаж для каждого дистрибьютора и расположить полученные результаты от наиболее высоких к низким.
Методы проверки статистических гипотез позволяют получить ответ на вопрос, являются ли обнаруженные закономерности подлинными, или же их можно объяснить случайными особенностями выборки. В частности, важным является вычисление стандартной ошибки среднего значения. Стандартная ошибка среднего значения необходима, чтобы определить, в какой области значений лежит истинное среднее значение генеральной совокупности. Для ее вычисления необходимо использовать пункты меню:
Statistics – Summarize – Frequencies - Statistics – S.E.Mean
(S.E.Mean – standard error Mean).
Для непрерывной переменной, как уже говорилось выше, вместо стандартной ошибки среднего используются нормированные значения (z-значения) и необходимо использовать:
Statistics – Summarize – Descriptives —
– выбор переменных – Save standartized values as variably.
Как было показано в Главе 2, для проверки нормальности распределения кривая нормального распределения может быть наложена на гистограмму. Для этого в программе SPSS требуется использовать пункты меню:
Statistics – Summarize – Frequencies – Charts – Histograms – With normal curve (рис. 3.6)

Рис. 3.6. Окно задания графиков в процедуре Frequencies
Таким образом, гипотеза нормальности может быть проверена графически.
Для проверки нормальности распределения могут использоваться показатели асимметрии (Skewness) и эксцесса (Kurtosis). Асимметрия показывает "скошенность" кривой распределения относительно нормальной кривой, а эксцесс замеряет "заостренность" кривой (положительный – заостренная кривая, отрицательный – "тупая"). Стандартная ошибка Std.Error позволяет оценить значимость асимметрии и эксцесса. Для вычисления этих показателей необходимо использовать пункты меню:
Statistics – Summarize – Frequencies —
— Statistics – Skewness, Kurtosis
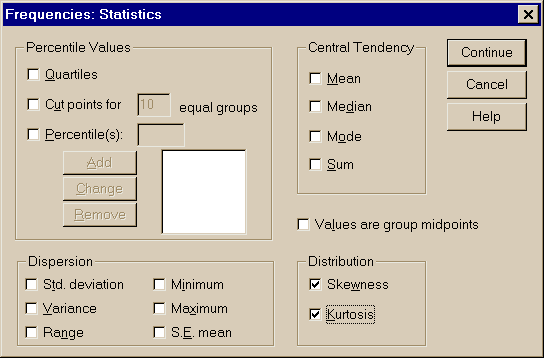
Рис. 3.7. Задание вычисления асимметрии и эксцесса
в процедуре Frequencies
Для предварительного вычисления многих параметров описательной статистики (минимум, максимум, среднеквадратическое отклонение, усеченное среднее и т.п.), можно использовать разведочный анализ - процедуру Explore:
Statistics – Summarize – Explore
– выбор переменной - Statistics…
Для проверки нормальности в этой процедуре вычисляются асимметрия, эксцесс, изображается диаграмма Stem-and-leaf - "ствол и листья", позволяющая оценить распределение:
Statistics – Summarize – Explore –
выбор переменной - Plots…- Stem-and-leaf
(Stem Width – ширина "ствола").
При интерпретации результатов необходимо учитывать, что диаграмма Stem-and-leaf в окне вывода программы SPSS располагается с наклоном 90о (рис. 3.8).
Age of Respondent Stem-and-Leaf Plot
Frequency Stem & Leaf
12,00 1 . 899 143,00 2 . 000011111111222222233333344444 150,00 2 . 5555556666666777777888888899999 187,00 3 . 00000001111111222222222333333334444444 195,00 3 . 555555555556666666777777788888889999999 167,00 4 . 0000000111111112222223333333444444 113,00 4 . 5555667777778888889999 87,00 5 . 000011122223334444 78,00 5 . 555667778888999 87,00 6 . 00011112223333444 84,00 6 . 555566677778888999 95,00 7 . 0001111222233333444 53,00 7 . 5566677889 43,00 8 . 001122234 20,00 8 . 5799& Stem width: 10 Each leaf: 5 case(s) & denotes fractional leaves.
Рис. 3.8. Пример диаграммы Stem-and-Leaf
Оценить вид распределения помогают также "ящичковые диаграммы", о которых упоминалось уже в Главе 2. Для вычисления "ящичковых диаграмм" используются пункты меню:
Statistics – Summarize – Explore
– выбор переменной – Plots… - Factor levels Together
Ящичковые диаграммы дают исследователю общее представление о распределении переменной: на них высота ящичка – разброс значений, жирная черта внутри – медиана или 50%- процентиль, нижняя грань – 25%-процентиль, верхняя – 75%-процентиль.
Значения, не попавшие внутрь, изображаются отдельно вне ящика.
Эти значения можно исследовать отдельно (если они есть):
Statistics – Summarize – Explore
– выбор переменной - Statistics…- Outliers
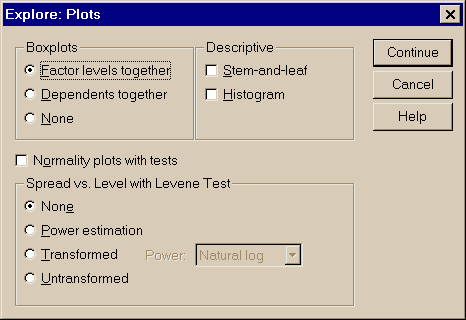
Рис. 3.9. Пример задания расчета ящичковой диаграммы
В окне вывода при таком исследовании выводится таблица экстремальных значений Extreme Values.
Одним из методов исследования нормальности распределения является также построение графиков на нормальной вероятностной бумаге. На графике даются координаты фактических значений переменных и теоретические значения, вычисленные при условии
нормальности распределения (линия). Чем ближе фактические значения к линии, тем больше распределение близко к нормальному. Аналогично можно интерпретировать график с удаленным трендом – Detrended Normal Q-Q Plot, - нормальному распределению здесь соответствует горизонтальная линия.
При построении графиков на нормальной вероятностной бумаге в программе SPSS автоматически рассчитываются значения коэффициентов Колмогорова-Смирнова и Шапиро-Уилкса. Эти критерии основаны на нулевой гипотезе о том, что данная выборка получена из генеральной совокупности, имеющей нормальное распределение. В окне вывода можно изучить Tests of Normality, особенно обращая внимание на уровень значимости каждого критерия Sig: если он больше 0.05 (т.е. превышает 5%), то можно принять нулевую гипотезу – или, строго говоря, нет оснований ее отвергнуть!
Существует большое количество методов проверки нормальности распределения, но ни один из них не является универсальным. Одни могут подтверждать нормальность, а другие – отвергать. Исследователю необходимо использовать все возможные методы для получения как можно менее противоречивых данных!
3.3. Построение таблиц сопряженности.
Каждая ячейка таблицы сопряженности содержит информацию о количестве объектов, попадающих в группу, определенную комбинацией двух значений. В применении к анализу опросных листов это означает, что исследователь может, например, получить информацию о количестве мужчин, имеющих информацию о товаре (количество человек, ответивших на вопрос о поле – "муж.", и на вопрос о известности товара – "известен").
Для вычисления таблиц сопряженности используются пункты меню (рис.3.10):
Statistics – Summarize – Crosstabs –
выбор переменных: Row - по строкам, Column - по столбцам
Помимо количества объектов, попадающих на комбинацию значений, в таблице можно вывести и процентные соотношения рис.3.11):
после выбора переменных –
Cells – Percentages – Total (по строкам и по столбцам)
Соотношения в таблицах сопряженности применимы только к выборке; для того, чтобы проверить, возможно ли распространить результаты на генеральную совокупность, необходимо использовать специальные критерии, описанные в Главе 2 и, в частности, вычислить критерий хи-квадрат Пирсона.
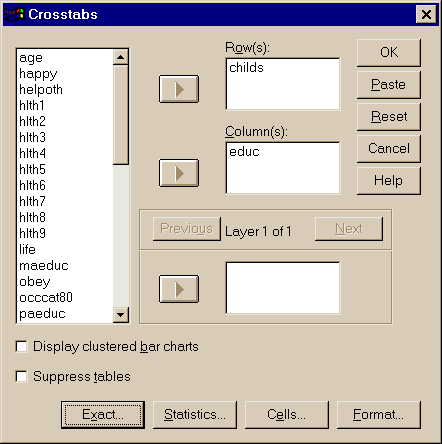
Рис. 3.10. Вычисление таблиц сопряженности
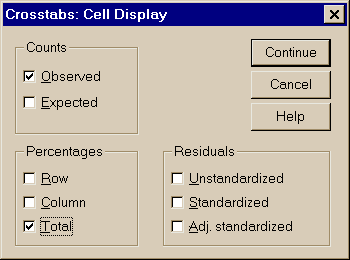
Рис. 3.11. К вычислению таблиц сопряженности
Нулевая гипотеза предполагает, что между переменными нет никакой зависимости. Используем пункты меню (рис.3.12):
Statistics – Summarize – Crosstabs - ……. ………-Statistics … - Chi-square

Рис. 3.12. Вычисление критерия хи-квадрат Пирсона
В таблицах окна вывода программы SPSS исследователь получает следующие результаты:
Pearson Chi-Square – хи-квадрат Пирсона.
Likelihood Ratio – отношение правдоподобия. Рассчитывается по более сложной формуле, чем хи-квадрат Пирсона (хи-квадрат представляет собой приблизительную оценку отношения правдоподобия).
Linear-by-Linear Association – критерий линейно-линейной зависимости. Представляет собой коэффициент корреляции, применим только если обе переменные – порядковые!
В таблице в окне вывода: Value – значения критерия, df - количество степеней свободы, Asymp.Sig.(2-sided)- уровень значимости (рис. 2.14 в Главе 2). Обычно нулевая гипотеза отвергается, если уровень значимости меньше 5% (0.05).
Для того, чтобы определить вклад каждой ячейки таблицы в общее значение критерия хи-квадрат, можно в меню:
Statistics – Summarize – Crosstabs - …….- Cells
выбрать для вывода также значения :
Expected – ожидаемое значение;
Unstandarized – ненормированные остатки;
Standarized – нормированные остатки
All Standarized – исправленные нормированные остатки (рис. 3.11).
Величины остатков позволяют судить о том, насколько сильно фактические значения отличаются от ожидаемых, или какие значения более всего отклоняются от нулевой гипотезы (если она верна, остатки должны быть равны нулю).
3.4. Вычисление корреляционных функций.
Как было показано в Главе 2, корреляция - это исследование комбинаций непрерывных переменных. Графическое представление зависимости между переменными можно получить с помощью диаграммы рассеяния. Для построения диаграммы рассеяния используются пункты меню:
Graphs – Scatter – Simple – Define – выбор переменных
Диаграмма позволяет на глаз оценить зависимость двух переменных.
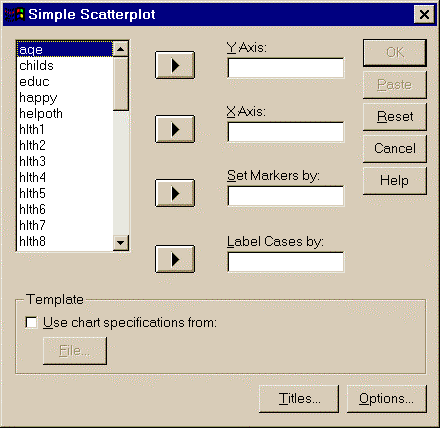
Рис. 3.13. Построение диаграммы рассеяния
Поверх уже созданной диаграммы в окне вывода можно наложить линию наименьших квадратов. В окне Редактора графиков (чтобы его вызвать, необходимо два раза щелкнуть левой клавишей мыши на графике в окне вывода) требуется задать: Charts – Options – Fit Line – Total

Рис. 3.14. Наложение линии наименьших квадратов поверх диаграммы рассеяния
Если требуется обнаружить квадратичную или кубическую зависимость, необходимо в окне редактора графиков выбирать Fit Options.
Информацию о зависимости между переменными можно получить, вычислив коэффициент корреляции Пирсона r:
r = 1 – прямая зависимость;
r = -1 - обратная зависимость;
r = 0 - отсутствие зависимости (вернее, в данном случае линейную зависимость установить не удается и можно попытаться установить нелинейную зависимость, используя диаграммы рассеяния – см. выше). Для вычисления коэффициента корреляции Пирсона используются пункты меню:
Statistics – Correlate - Bivariate –
выбор переменных – Correlation Coefficients - Pearson
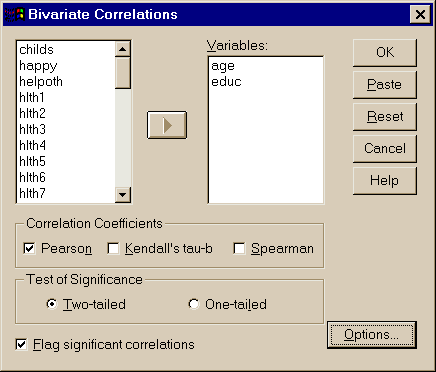
Рис. 3.15. Вычисление коэффициента корреляции Пирсона
Для каждой выбранной пары переменных принимается нулевая гипотеза о том, что линейная зависимость между ними отсутствует.
Результаты вычислений помещаются в таблицу Correlations в окне вывода (рис.2.11, Глава 2):
Pearson Correlation – коэффициент корреляции;
Sig. (2-tailed) – уровень значимости коэффициента;
N - количество записей в файле данных, по которым делался расчет.
Особое внимание следует обратить на уровень значимости – любая значимость выше 0.05 (5%) подтверждает нулевую гипотезу (о том, что в генеральной совокупности значение коэффициента корреляции равно нулю).
Для использования коэффициента корреляции Пирсона необходимо, чтобы все переменные были непрерывными и данные являлись бы случайной выборкой из генеральной совокупности с нормальным распределением. В том случае, когда какое-либо из этих условий не выполняется и коэффициент Пирсона использовать нельзя, применяются так называемые непараметрические критерии и, в частности, коэффициент ранговой корреляции Спирмена. Его значение также заключено между –1 и +1, интерпретация осуществляется так же, как и интерпретация значений коэффициента Пирсона.
Statistics – Correlate - Bivariate – выбор переменных —
— Correlation Coefficients - Spearman
Коэффициент Спирмена менее мощный, чем коэффициент Пирсона, поскольку в нем используется меньше информации о данных; тем не менее он является весьма полезным и часто используется в случае невозможности использования критерия Пирсона.
Как уже подчеркивалось в Главе 2, при интерпретации результатов исследования комбинации переменных с помощью корреляции, необходимо помнить, что сильная корреляционная зависимость между переменными совсем не означает, что одна является причиной другой!
3.5. Расчет t-критерия.
t–критерий применяется для сравнения двух групп, образованных категориями независимой переменной по характеристикам распределения зависимой непрерывной переменной.
В основе t-критерия лежат следующие предположения.
- Две группы являются взаимоисключающими, т.е. каждое наблюдение может попасть только в одну из этих групп.
- Данные получены в результате случайной выборки из генеральной совокупности с нормальным распределением непрерывной переменной.
- В генеральной совокупности в обеих группах одинаковая дисперсия непрерывной переменной
Как правило, перед расчетом t-критерия осуществляется проверка двух последних предположений. Для проверки равенства дисперсий используется критерий Ливиня (Levene test), который более устойчив к нарушению нормальности распределения, чем другие критерии; в программе SPSS он автоматически рассчитывается при расчете t-критерия. Нулевая гипотеза, которую проверяет критерий Ливиня – равенство внутригрупповых дисперсий.
Как и все виды генерализующей статистики, t-критерий используется для того, чтобы на основе данных нашей выборки оценить вероятность того, что обнаруженные различия являются подлинными (существующими в генеральной совокупности), а не вызваны исключительно случайной ошибкой выборки.
Нулевая гипотеза состоит в том, что средние значения исследуемой переменной в группах равны (применительно к обработке опросного листа - например, в группе мужчин и группе женщин).
Для расчета t-критерия используются пункты меню:
Statistics – Compare Means – Independent Samples T Test – — выбор переменных – для переменной Grouping Variable определить группы – Define Groups
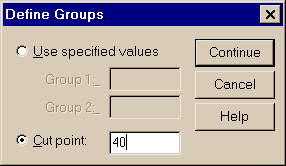

Рис. 3.16. Формирование задания для вычисление t- критерия
Результаты вычислений в окне вывода находятся в таблице Group Statistics (рис.2.15, Глава 2):
Levene's Test for Equality of Variances – критерий равенства дисперсий Ливиня. Приводится значение критерия F и уровень его значимости Sig. Если уровень значимости критерия ниже 0.05, то нулевая гипотеза о равенстве дисперсий отвергается, и можно использовать только вторую строку таблицы – Equal variances not assumed (равенство дисперсий не предполагается). В противном случае используется первая строка.
t - значение t-критерия. Показывает направление и степень межгруппового различия средних.
Sig (2-tailed) – уровень значимости t-критерия. Если уровень значимости больше 0.05, принимается нулевая гипотеза о равенстве средних в подгруппах; в противном случае – отвергается.
В том случае, если данные не удовлетворяют требованиям t-критерия (например, невозможно установить, что групповые дисперсии равны), можно использовать непараметрические критерии. Наиболее подходящим непараметрическим критерием, заменяющим t-критерий, является критерий Манна-Уитни (обозначается буквой U). Для расчета значения критерия подгруппы ранжируются; нулевая гипотеза состоит в том, что суммы рангов в обеих группах должны быть равными, и рассчитываемый уровень вероятности показывает вероятность этой гипотезы.
Для расчета значения критерия применяются пункты меню (рис. 3.17): Statistics – Nonparametric Tests – 2 Independent Sample –
выбор переменных — Test Variable List, Grouping Variable Define Variable — Mann-Whitney U

Рис. 3.17. Вычисление критерия Манна-Уитни
Интерпретация результатов совершенно аналогична интерпретации результатов вычисления t-критерия. Если symp. Sig. (2-tailed) – рассчитанный уровень вероятности, - 0.05, то нет оснований отвергнуть нулевую гипотезу.
Хотя непараметрический критерий Манна-Уитни менее мощный, чем t-критерий, поскольку он использует меньше информации о данных, этот критерий часто используется в тех случаях, когда нет уверенности в том, что данные соответствуют условиям применимости t-критерия.
3.6. Регрессионный анализ.
Линейный регрессионный анализ позволяет получить предсказание значений зависимой переменной на основе значений независимых переменных.
Линейный регрессионный анализ является достаточно сложной статистической процедурой. Поэтому здесь ограничимся рассмотрением случая одной зависимой и одной независимой переменной и будем использовать процедуру простой линейной регрессии.
Для расчета линейной модели регрессии необходимо использовать пункты меню (рис. 3.18):
Statistics – Regression - Linear –
выбрать переменную и поместить ее в окно Dependent (зависимая переменная) – выбрать переменную и поместить ее в окно Independet(s) (независимые переменные).
Нажав кнопку Statistics… можно задать расчет ряда коэффициентов регрессии, нажав кнопку Plots… - вид выводимых графиков в процедуре линейной регрессии (рис. 3.19), можно задать сохранение результатов процедуры "Линейная регрессия" (кнопка Save…) и параметры процедуры регрессии (кнопка Options…)

Рис. 3.18. Вычисление регрессионной модели
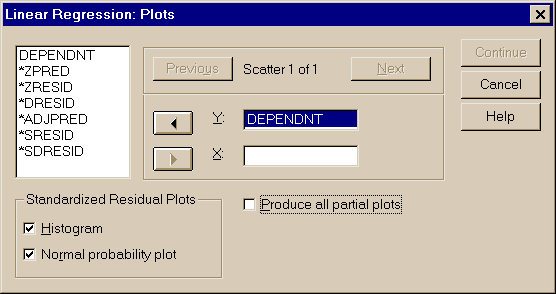
Рис. 3.19. Задание на расчет коэффициентов регрессии и вида графиков
При интерпретации результатов, полученных в окне вывода программы SPSS, необходимо учитывать, что некоторые выходные данные требуются только при построении сложных регрессионных моделей. Поэтому рассмотрим только основные элементы выходных данных (рис. 2.19, Глава 2).
В сноске к таблице Model Summary дается информация, которая показывает, насколько хорошо можно представить значение зависимой переменной на основе независимой:
R – коэффициент корреляции между переменными;
R-square - квадрат коэффициента корреляции (показывает, какая часть изменчивости зависимой переменной может быть объяснена независимой переменной).
При интерпретации выходных данных необходимо учитывать значимость коэффициентов (столбец Sig. таблицы ANOVA): линейная регрессионная модель зависимости является надежной, если уровень значимости не превышает 0.05 (5%).
В таблице Coefficients (коэффициенты) приводятся рассчитанные коэффициенты регрессионной модели: регрессионный коэффициент (тангенс угла наклона прямой), а также постоянная прямой. Значение в первой строке столбца В таблицы (Constant) – постоянная, во второй (где приведено имя переменной) – коэффициент (тангенс угла наклона прямой). С помощью этих чисел можно записать уравнение прямой:
Зависимая переменная = Коэффициент * Независимая
переменная + Постоянная
Теперь, используя это уравнение, можно по заданному значению независимой переменной вычислять значения (предсказанные) зависимой переменной.
В столбце Sig. таблицы Coefficients представлен уровень значимости для каждого регрессионного коэффициента. При 5%-ном уровне значимости можно считать неравными нулю только те коэффициенты, для которых значение Sig. не превышает 0.05.
3.7. Редактирование таблиц и графиков в окне Навигатора
Вывода.
Результаты выполнения процедур SPSS выводятся в окно, называемое Output Navigator (Навигатор Вывода). Непосредственно в окне Навигатора можно отредактировать выводимые результаты и создать документ, содержащий именно то, что необходимо исследователю для создания полноценного отчета о результатах анализа опросных листов.
Навигатор вывода можно использовать для того, чтобы:
- просматривать выводимые данные;
- показывать или скрывать выбранные таблицы и диаграммы;
- изменять порядок следования элементов вывода;
- переходить к Редактору Таблиц, Редактору Текста или Редактору Диаграмм;
- перемещать объекты SPSS в другие приложения (например, документ текстового редактора Word).
Окно навигатора (рис. 3.20) разделено на две части - в левой находится схема вывода, в правой - сами результаты (статистические таблицы, диаграммы, текст). Пользователь может передвигать границу между этими частями, если он захочет изменить ширину левой или правой части.
Содержимое окна Навигатора может быть сохранено в документе во внутреннем формате SPSS - *.spo, для чего необходимо использовать:
File - Save (Save As …),
а для сохранения вывода во внешних форматах (текстовом, HTML), использовать:
File - Export - Тип файла
Рис. 3.20. Окно навигатора вывода
Для того, чтобы скрыть таблицу или диаграмму, не удаляя их, необходимо щелкнуть дважды на пиктограмме, изображающей открытую книгу, в левой части Навигатора Вывода, либо выбрать в меню: View - Hide.
Перемещение, копирование и удаление результатов можно производить либо с помощью мыши, перетаскивая при нажатой левой клавише нужные элементы в левой часто окна навигатора, либо используя элементы меню:
Edit - Cut, Copy, Copy Objects, Delete
Для изменения размеров элементов в схеме нужно выбрать View -, Outline Size, а для изменения шрифта View - Outline Font.
Большинство результатов в SPSS выводится в форме таблиц. Их вид может быть изменен пользователем, который может управлять представлением строк, столбцов и слоев таблицы. Таблицы такого типа называются в SPSS "pivot table" (мобильная таблица). Для редактирования таблицы необходимо два раза щелкнуть на ней в правой части окна Навигатора Вывода. Это действие запускает Редактор Мобильной Таблицы. Используя пункт меню Pivot - Pivoting  Trays, можно активизировать окно Pivoting Trays 1 (рис. 3.21), в котором пользователю предоставляется возможность пере-
Trays, можно активизировать окно Pivoting Trays 1 (рис. 3.21), в котором пользователю предоставляется возможность пере-
Рис. 3.21. Окно Pivoting Trays группировки данных в таблице(изме-нения меток строк и столбцов, порядок отображения категорий и т.п.).
Используя Редактор Мобильной Таблицы можно перемещать и менять местами строки (столбцы), поворачивать метки строк и столбцов: Format - Rotate Inner Column Labels или Rotate Outer Row Labels.
Можно изменять общий вид таблицы, применив к ней один из элементов Table Looks (Стиль таблицы). Диалоговое окно Table Properties (Свойства таблицы) дает возможность устанавливать и менять общие свойства таблицы, такие как сокрытие пустых строк или столбцов и разбивка таблицы на страницы при печати, определение формата отдельных ячеек, изменение рамок и т.п.
В Редакторе Таблицы можно задать характеристики шрифта для разных областей таблицы вплоть до любой отдельной ячейки:
Format - Font.
Некоторые элементы вывода в программе SPSS отображаются только в виде текста, а не в виде таблицы или диаграммы. Эти текстовые элементы отображаются равномерным шрифтом, например Courier. Равномерный шрифт позволяет выравнивать содержимое вывода, например, диаграмму "ствол - и - листья". Содержимое текстового вывода можно редактировать, используя стандартные возможности Windows, либо скопировав это содержимое в текстовый редактор (например, Word). В окно Навигатора Вывода могут также быть добавлены текстовые элементы, не соединенные ни с какой таблицей или диаграммой. Для этого необходимо щелкнуть мышью на объекте Навигатора, который должен предшествовать вставляемому текстовому элементу, выбрать в меню: Insert - New Title или Insert - New Text, щелкнуть дважды на новом объекте и вводить текст в появившееся поле.
Для редактирования графиков и диаграмм нужно дважды щелкнуть мышью на нужной диаграмме, при этом запускается Редактор Графиков - Chart Editor (рис. 3.22).
Рис. 3.22. Окно Редактора Графиков
Используя Редактор, пользователь может преобразовать этот график или воспользоваться имеющимся списком типов графиков и представить те же данные в другом виде, а также:
- редактировать заголовки и метки осей;
- редактировать цвета и способы заштриховки столбиков;
- добавлять заголовки;
- изменять положение осевой линии графика;
- добавлять аннотации;
- добавлять внешнюю рамку и т.д.
На рис.3.23 показан пример преобразованного графика, изображенного в окне вывода на рис. 3.22 в виде круговой диаграммы.
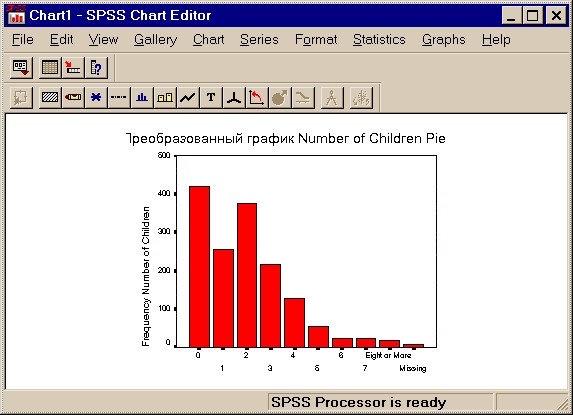
Рис. 3.23. Пример преобразованного графика
Итак, редактировать таблицы и графики в окнах вывода (Output) программы SPSS можно только предварительно поставив на них курсор мыши и щелкнув два раза левой клавишей. При этом загружаются специальные приложения SPSS, позволяющие вносить необходимые изменения в элементы выводимой информации и формировать полноценные отчеты.
Для экспорта элементов вывода (таблиц, диаграмм, можно использовать пункты меню File - Export и работать со специальным диалоговым окном (рис.3.24) или просто щелкнуть правой клавишей мыши на нужном объекте и выбрать требуемую операцию (Cut, Copy, Copy Objects …).
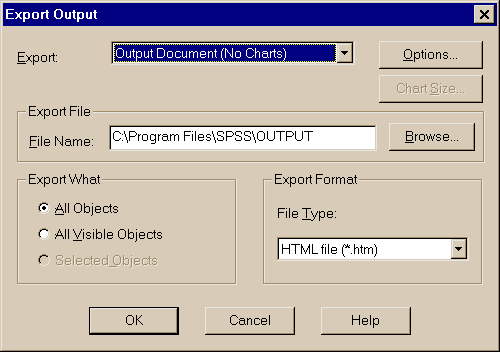
Рис. 3.24. Задание экспорта данных
Данные могут быть экспортированы, например, в текстовый редактор Word и вставлены в аналитический раздел итогового отчета о маркетинговых исследованиях.
При самостоятельной работе с программой SPSS исследователь может использовать мощные возможности поддержки пользователя. Пункт основного меню Help позволяет получать справки, подсказки, изучать примеры и уроки, для более правильного понимания используемых статистических методов и верной интерпретации получаемых результатов.
