Собирайте все что можно: получение и хранение данных
Карл Андерсон
Глава из книги «Аналитическая культура. От сбора данных до бизнес-результатов»
Издательство "Манн, Иванов и Фербер"
Чарльз Бэббидж1
Тим Бернерс-Ли2
В предыдущей главе мы обсудили вопросы качества данных и их правильного сбора. В этой главе фокус сместится на выбор правильных источников для сбора данных и предоставления специалистам по аналитике. Мы остановимся на следующих вопросах: как расставить приоритеты при выборе источников данных, как осуществить сбор данных, как определить ценность данных для компании.
Собирайте все что можно
Предположим, вы внедряете новый процесс оформления и оплаты заказов на сайте. Вас интересует, как именно он работает по сравнению с вашими показателями. Для этого вы можете проанализировать конверсию, размер корзины и другие параметры. Кроме того, вам было бы весьма полезно понять, как этот новый процесс воспринимается со стороны покупателей. Например, на некоторых сайтах добавление товара в корзину происходит в один клик мыши, так что модель поведения покупателя может быть следующей: он добавляет в корзину все, что его заинтересовало, а перед оформлением заказа делает окончательный выбор, удаляя лишнее. На других сайтах добавление товаров в корзину и удаление из нее происходит не так просто, и фактически покупателю нужно принять окончательное решение перед добавлением товара в корзину. Очевидно, что всестороннее изучение и измерение процесса оформления и оплаты заказов помогает лучше его понять и внести изменения или улучшения.
В своей книге Building Data Science Teams3 Ди Джей Патиль отмечает:
Легко сделать вид, что вы действуете на основании анализа данных. Но если на самом деле собирать и измерять все доступные вам данные и думать о том, что означают собранные вами данные, вы намного опередите все те компании, которые лишь заявляют об управлении на основе данных.
Собирайте все доступные данные. Никогда не знаешь, какая информация может понадобиться, а шанс собрать данные часто выдается только один, и вы будете кусать локти, когда поймете, что нужная вам информация больше недоступна. Чем больше данных вы соберете, тем больше вероятность, что вам удастся смоделировать и понять поведение пользователей (как в примере с процессом оформления и оплаты заказа) и, что более важно, понять контекст их действий. Контекст — наше все. Таким образом, чем лучше компания поймет своих покупателей, их вкусы, намерения, желания, тем успешнее ей удастся улучшить пользовательский опыт своих клиентов благодаря персонализации, рекомендациям или совершенствованию сервиса, что будет способствовать возникновению так называемого длинного хвоста4.
При разработке онлайновых продуктов сбор абсолютно всех данных нельзя считать чем-то уникальным. Вы контролируете источник данных: сбор информации относительно одной какой-то характеристики может проводиться с помощью того же самого или похожего механизма, что и сбор информации относительно другой характеристики. То есть существует возможность использования общих шаблонов, потоков данных и механизмов хранения. Компания, в которой действительно уделяется большое внимание данным, вероятно, будет характеризоваться более широким горизонтом мышления. В такой компании все остальные функции также окажутся организованы на основе данных: маркетинг, продажи, обслуживание клиентов, цепочка поставок, работа с персоналом. Если по каждому из этих направлений имеется набор внутренних и внешних источников данных в разных форматах, с разным временем ожидания, проблемами с качеством данных, с разными требованиями к безопасности и соответствия нормативам и так далее, то это начинает превышать возможности команды специалистов по работе с данными. Это тот случай, когда «собирать все что можно» звучит как отличная идея, которая оборачивается серьезной «головной болью», когда доходит до дела.
Более того, этот процесс требует финансовых затрат. Чем больше данных, тем лучше5 (см. приложение А, где приведены примеры и объяснение, почему это так), но какую цену компания за это платит? На создание инфраструктуры для сбора, очистки, трансформации и хранения данных нужны средства. Компания несет издержки на поддержание работоспособности этой инфраструктуры, резервное копирование данных, интеграцию источников этих данных для обеспечения целостной картины бизнеса. Кроме того, возможны значительные дальнейшие издержки на обеспечение качественного инструментария для специалистов по анализу данных, чтобы они могли максимально эффективно использовать эти несопоставимые источники данных. Компании не обойтись без всего этого, если она стремится, чтобы правильные данные попали в руки специалистов по анализу.
Основные характеристики больших данных
Специалисты по большим данным выделяют три аспекта сбора и обработки большого количества данных: объем, разнообразие и скорость6.
Объем
Объем данных напрямую влияет на издержки на их хранение и изменения. Хотя абсолютно верно, что расходы на хранение данных снижаются экспоненциально (сегодня хранение информации обходится в 0,03 долл. за GB по сравнению с примерно 10 долл. за GB в 2000 году), число доступных источников данных повысилось настолько значительно, что это перекрывает снижение затрат на хранение информации.
Разнообразие
Это еще один важный аспект данных. С одной стороны, разнообразный набор источников способен обеспечить более богатый контекст и более полную картину. Таким образом, прогноз погоды, данные по инфляции, сообщения в социальных медиа могут оказаться весьма полезными для понимания продаж ваших продуктов. При этом, чем разнообразнее тип данных и источники данных (CSV-файлы из одного источника, объекты JavaScript (JSON) из другого источника, почасовой прогноз погоды отображается здесь, а данные о запасах — здесь), тем выше будут издержки на интеграцию. Довольно сложно собрать все данные вместе, чтобы получить общую картину.
Скорость
Объем данных, который требуется обработать в единицу времени. Представьте, что в ходе дебатов кандидатов в президенты вам нужно проанализировать сообщения в Twitter, чтобы вывести общее настроение избирателей. Необходимо не только обработать огромный объем информации, но также оперативно предоставить обобщенную информацию о настроении нации относительно комментариев во время дебатов. Масштабная обработка данных в режиме реального времени — процесс сложный и дорогостоящий.
(В некоторых случаях компании выделяют еще один аспект — «достоверность», для характеристики качества данных.)
Даже компаниям, сегодня собирающим огромные объемы данных, например Facebook, Google и Агентству национальной безопасности США (NSA), на это потребовалось время. Только со временем удается выстроить источники данных, взаимосвязи между ними и возможности обработки данных. Требуется рациональная и тщательно продуманная стратегия обеспечения данными. Более того, в большинстве компаний команды, работающие с данными, ограничены в ресурсах: они не в состоянии делать все и сразу, так что им приходится расставлять приоритеты, с какими источниками данных работать в первую очередь. Реальность такова, что процесс сбора данных идет медленно и последовательно: всегда возникают непредвиденные задержки и проблемы, так что приходится сосредоточиваться на ценности, рентабельности инвестиций и влиянии, которое новый источник данных окажет на компанию. Этому и будет посвящена данная глава.
Расстановка приоритетов при выборе источников данных
В обычных малых или средних компаниях, ограниченных в ресурсах, специалистам по работе с данными, как правило, приходится выбирать, с каким источником данных работать. Чем они при этом руководствуются? Определяя приоритеты при выборе источников данных, компания, в которой управление осуществляется на основе данных, должна сосредоточиться на таком важном аспекте, как ценность данных для бизнеса.
Основная цель команды по работе с данными заключается в том, чтобы предоставлять данные, отвечающие потребностям определенных подразделений компании и их аналитиков, и помогать оказывать влияние на эффективность деятельности компании. У каждой команды или подразделения, как правило, имеется набор «основных» данных. Например, для специалистов по обслуживанию клиентов это могут быть данные по взаимодействию с ними посредством электронной почты, телефонных звонков, социальных медиа, данные по заказам клиентов, а также разбор конкретных ситуаций. На основе этих данных команда может выполнять свои основные функции — максимально эффективно обслуживать клиентов. Кроме того, специалисты могут объединить эти источники для создания целостного взгляда на сценарии взаимодействия с клиентами. Они могут предоставить обобщенные показатели продуктивности работы команды, такие как среднее время решения проблемы клиента, а также проанализировать тип взаимодействий в случае каждого источника. У каждой команды специалистов должны быть свои основные данные. Однако, помимо этого, у них могут быть и другие данные, способные дополнить основной набор. Например, коэффициент дефектности продукции или данные A/B-тестирования, проясняющие, какая новая характеристика товара привела клиентов в замешательство. На основе этих данных специалисты могут прогнозировать частоту и характер ситуаций при работе с клиентами, которых можно ожидать. Эти другие источники данных также могут быть ценными и оказывать влияние, но они не критические.
Проблема компании с ограниченными ресурсами в том, что команда специалистов по работе с клиентами — лишь одна из многих.
У команд специалистов в других областях есть свои наборы основных данных и свои пожелания относительно информации, «которую было бы неплохо иметь». Специалист по работе с данными или руководитель команды по работе с данными вынужден уравновешивать все эти запросы от разных команд специалистов. В табл. 1 приводится ряд показателей, способных помочь в расстановке приоритетов. Основной фактор — рентабельность инвестиций (ROI), но стоит принимать во внимание и другие факторы, такие как доступность, полнота, качество данных и некоторые другие.
Таблица 1. Аспекты, на которые следует обратить внимание при расстановке приоритетов при выборе новых источников данных в условиях ограниченности ресурсов
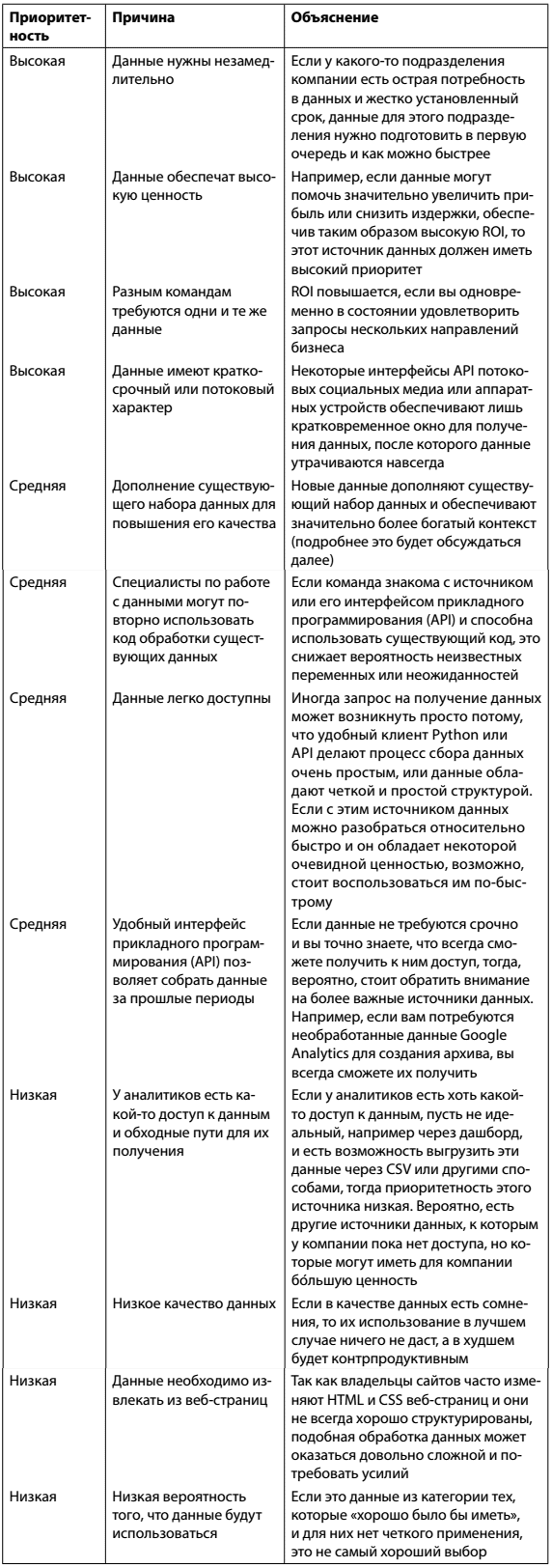
Очевидно, что самые разные, нередко конкурирующие аспекты определяют, какой новый источник данных целесообразно использовать в компании. Существует тонкий баланс между издержками на приобретение новых данных и сложностью этого процесса и той ценностью, которую эти данные имеют для аналитиков и компании в целом.
Установление взаимосвязи
Очевидно, что для проведения более глубокого анализа важное значение имеет сбор данных внутри компании: вы получаете определенные данные из отдела маркетинга, данные из отдела продаж, данные по цепочке поставок. Однако еще большую ценность эти данные обретают, когда вы начинаете устанавливать взаимосвязи между смежными данными. Что я имею в виду?
Представьте, что вам предложили тысячу элементов для составления пазла, но на коробке при этом нет изображения того, что должно в итоге получиться. По мере сортировки элементов вы выделили группу элементов голубого цвета. Вероятно, это небо. Группа элементов зеленого цвета может изображать траву. Вот вы нашли глаз. Но чей — животного или человека? У вас появляется смутное представление о картинке в целом, но не хватает деталей. Детали возникают, когда вы начинаете соединять смежные элементы, например элементы с изображением глаза и элементы с изображением уха. Появилась ясность. Давайте рассмотрим эту ситуацию с точки зрения аналитики.
Предположим, вы пользуетесь сервисом Google Analytics для анализа того, как пользователи попадают на ваш сайт. Вы получаете подборку веб-страниц, с которых произошел переход на ваш сайт, а также список поисковых запросов, географию пользователей и так далее, что дает вам общее представление о выборке пользователей или генеральной совокупности (это условные «кусочки неба»). Вы анализируете результаты опроса покупателей за последние три месяца: 75% респондентов нравится цена, 20% похвалили качественное обслуживание и так далее (это «кусочки травы»). У вас складывается общее представление о состоянии дел, но весьма поверхностное, так как данные остаются разрозненными.
Теперь, наоборот, представим, что мы имеем дело с одним заказом (см. рис. 1). Белинда Смит заказывает комплект садовой мебели. Если сопоставить ее заказ с сессией, во время которой она совершила покупку, можно сделать определенные выводы: она потратила 30 минут на просмотр 15 разных комплектов садовой мебели, прежде чем остановилась на одном. Очевидно, у нее не было четкого представления, какой комплект она ищет. Как она попала на страницу компании? Если добавить сопутствующую информацию, выяснится, что она ввела поисковый запрос в Google и перешла на сайт компании. Это подтверждает наше предположение относительно ее пользовательского поведения. Если к этому добавить полную историю ее онлайновых покупок, можно сделать вывод, что Белинда часто покупает товары для дома, а за последний месяц количество таких покупок у нее резко увеличилось. Те факты, что Белинда часто совершает покупки онлайн и пользуется поисковым сервисом Google, позволяют предположить, что у нее нет лояльности к конкретным брендам и компании придется постараться, чтобы она совершила повторную покупку. Каждый раз, добавляя новый элемент информации на индивидуальном уровне, вы начинаете лучше понимать этого покупателя. Продолжим. На основе данных переписи населения США определим вероятный пол по имени: Белинда практически наверняка женщина. Отлично. При оплате покупки она указала адрес доставки. Попробуем извлечь демографические данные на основании индекса. Это пригород с большими земельными участками, где живут состоятельные люди. Как еще можно проверить этот адрес? «Пробьем» его по единой базе данных недвижимости (MLS). Интересно, база данных показывает, что это дом с бассейном. Эту информацию можно использовать для полезных рекомендаций. Что еще? Дом был продан всего шесть недель назад. Ага, вероятно, Белинда только что въехала в новый дом. По результатам другого проведенного нами анализа известно, что новоселы часто покупают коврики, кровати и лампы (да, так и есть, я сам проводил этот анализ). Наконец, она нажала на виджет «приведи друга», чтобы получить купон при оформлении заказа. Так как она приняла условия пользовательского соглашения с Facebook, это открыло ее социальную сеть.
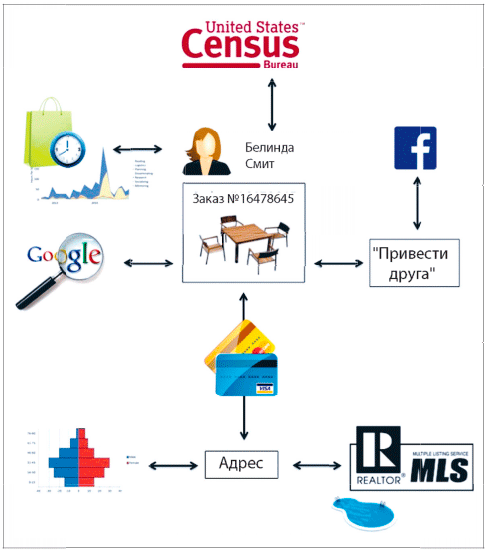
Рис. 1. Определение более широкого контекста для заказа Белинды
на основе разных источников данных
Источник: https://www.slideshare.net/CarlAnderson4/ddo-seattle
Для аналитика этот подробный профиль и контекст предлагают огромный объем сырых данных, с которыми можно работать. Специалист получает четкое представление о демографических данных клиента, истории его покупок и, в этом случае, даже о его мотивации. Проведите такой анализ для других ваших клиентов и автоматизируйте хотя бы часть этого анализа — и вы получите значительное стратегическое преимущество.
Установление взаимосвязи между элементами информации на этом индивидуальном уровне, в противоположность уровню сегмента, имеет огромную ценность и должно влиять на решения о том, какой набор данных использовать следующим (без нарушения этических норм и границ конфиденциальности), а также как связать эти данные с уже имеющимися на индивидуальном уровне.
Сбор данных
Теперь, когда мы разобрались, какие данные нужно собирать, давайте кратко остановимся на вопросе, как это делать.
В случае со многими источниками можно просто системно собирать все доступные данные. Есть много способов управления потоками данных. Можно воспользоваться интерфейсом прикладного программирования (API) или собирать файлы с FTP-сервера, можно даже проводить анализ экранных данных и сохранять что необходимо. Если это одноразовая задача, с ней легко справиться. Однако при частом обновлении или добавлении данных нужно решить, как работать с этим потоком. Для небольших таблиц или файлов может быть проще полностью заменять их новым, более масштабным набором данных. В моей команде маленькими у нас считаются таблицы с количеством строк до 100 тысяч включительно. Для работы с более крупными массивами данных необходимо установить более сложный процесс с анализом изменений. В самом простом случае новые данные всегда вносятся в новые ряды (например, журналы транзакций, где не должно быть обновлений или удалений текущих данных). В этом случае можно просто добавить (INSERT) новые данные в таблицу с текущими данными.
В более сложных случаях необходимо решить, будете ли вы добавлять (INSERT) строку с новыми данными, удалять (DELETE) или обновлять (UPDATE).
Для других источников данных может потребоваться сделать выборку. Проведение опросов и обработка результатов иногда бывает слишком дорогостоящим процессом, так же как и проведение клинических исследований или анализ всех записей в Twitter. То, каким образом осуществляется выборка, оказывает огромное влияние на качество данных. Однако необъективная выборка в значительной степени влияет на качество данных и возможность их использования. Самый простой подход заключается в формировании «простой случайной выборки», когда данные, которые будут включены в выборку, определяются простым подбрасыванием монетки. Суть в том, чтобы выборка была действительно репрезентативной относительно более крупного массива данных, из которого она формируется.
Внимательно стоит отнестись к формированию выборки данных, которые собираются в течение определенного периода времени. Предположим, вам требуется выборка сессий сайта за день. Вы отбираете 10% сессий и загружаете информацию о них в базу данных для последующего анализа. Если вы проделываете эту процедуру ежедневно, у вас формируется набор независимых сессий, выбранных случайным образом, но при этом вы можете упустить данные о пользователях, которые посетят сайт в последующие дни. То есть в выборке может не оказаться информации о пользователях с несколькими сессиями: они могут попасть в выборку в понедельник, но не попадут туда при их возвращении на сайт в среду. Таким образом, если вас больше интересуют последующие повторные сессии, а пользователи вашего сайта часто возвращаются, для вас может быть эффективнее выбрать случайным образом посетителей и отслеживать их сессии на протяжении определенного времени, чем делать случайную выборку сессий. В этом случае вы получите для работы данные более высокого качества. (Хотя, возможно, вам будет не слишком приятно наблюдать за пользователями, которые не возвращаются на сайт.) Механизм формирования выборки должен определяться тем бизнес-вопросом, ответ на который вы ищете.
И последнее: следует ли собирать сырые или агрегированные данные? Некоторые поставщики данных предлагают дашборды, где данные агрегированы в соответствии с ключевыми показателями, необходимыми аналитикам. Для аналитиков это может оказаться большим подспорьем. Однако если данные действительно ценные, для аналитиков такого подхода будет недостаточно: они непременно захотят еще больше углубиться в их изучение и рассмотреть их с самых разных сторон, а с дашбордами сделать это не удастся. Все эти отчеты и да-шборды эффективно использовать для архивного хранения данных. В других случаях, как показывает мой опыт, лучше по возможности собирать сырые данные, так как вы всегда сможете агрегировать их согласно показателям, но не наоборот. Имея сырые данные, вы сможете работать с ними как вам потребуется. Конечно, бывают редкие случаи, когда сбор сырых данных нерационален, например в силу большого их объема и высокой стоимости хранения или по причине того, что поставщик данных предлагает ценный сервис для обработки этих показателей (что вы не сможете сделать самостоятельно), но в большинстве случаев сбор сырых данных все-таки предпочтителен.
Покупка данных
Как правило, внутренние системы сбора данных в компании обеспечивают огромные массивы информации, которые можно дополнить данными, находящимися в открытом доступе, хотя иногда нужно заплатить за получение дополнительных данных от третьих сторон.
Существует множество причин, по которым вам может потребоваться покупать данные. Ранее мы анализировали заказ Белинды Смит на комплект садовой мебели, чтобы показать значимость контекста. Во-первых, другие партнеры, поставщики или даже государственные структуры могут располагать данными, способными обеспечить нужный контекст и добавить в вашу головоломку смежные элементы. Во-вторых, вы можете обладать внутренними данными, но данные третьей стороны могут выигрывать по объему или качеству.
В некоторых случаях выбор мест, где приобретать данные, может оказаться ограниченным. Например, единая база данных недвижимости (MLS) практически монопольно предоставляет информацию по сделкам. В других случаях возможна прямая конкуренция. Например, данные по профилям клиентов на основании их покупок, оплаченных с помощью кредитных карт, можно приобрести у нескольких компаний: Datalogix, Axciom, Epsilon или Experian. Это рыночные условия в действии.
При выборе между несколькими источниками данных, например при приобретении базы данных, в которой почтовые индексы соотнесены с местностью на карте, необходимо принять во внимание несколько факторов, в том числе перечисленные ниже.
Цена
Аналитики и их боссы любят «халяву», но иногда стоит заплатить за данные высокого качества. Следует взвесить, насколько рациональна цена и какой ценностью эти данные обладают для компании. Подробнее об этом мы поговорим в следующем разделе.
Качество
Насколько чисты и надежны эти данные?
Эксклюзивность
Подготовлен ли этот набор данных исключительно для вас и получите ли вы с его помощью преимущество перед конкурентами?
Выборка
Можно ли получить выборку, которая позволит судить о качестве и характере данных, а также понять формат без необходимости предварительно брать на себя обязательства?
Обновления
Насколько часто данные меняются или устаревают? Насколько часто данные обновляются?
Надежность
При обращении к интерфейсу прикладного программирования (API) каково время работоспособности системы? Каковы ограничения по обращениям к API или по другим сервисным соглашениям?
Безопасность
В случае, если данные важны, осуществляется ли их шифровка и какие меры безопасности предпринимаются при передаче?
Условия использования
Есть ли условия лицензирования или другие ограничения, которые могут не позволить воспользоваться данными в полной мере?
Формат
У всех есть любимые форматы данных, тем не менее обычно предпочтительно использование форматов, удобных для восприятия человеком, таких как CSV, JSON или XML (это подразумевает исключение бинарных форматов, кроме стандартного сжатия), так как эти форматы более удобны для использования при проведении анализа. Наконец, насколько просто вам будет поддерживать этот формат? Не потребуется ли от вас дополнительных вложений и времени на работу с этим форматом?
Документация
Предпочтение следует отдавать источникам, способным предоставить документацию. Обычно стоит поинтересоваться, как осуществляется сбор данных (чтобы понять, насколько они надежны и представляют ли они ценность для компании) и есть ли словарь данных (в нем указываются поля, тип данных, примеры значений и другая важная бизнес-логика, включенная в значения этих полей; см. табл. 2). Рэндалл Гроссмен, CDO корпорации Fulton Financial, заметил: «Словарь данных, которому можно доверять, — это самое важное, что CDO может предложить бизнес-пользователям».
Объем
Сможете ли вы обеспечить хранение большого объема данных? При этом ценные наборы данных не обязательно бывают большими. Например, почтовый индекс для расчетной рыночной территории (то есть территории охвата конкретного региона телевещанием, по оценке компании Nielsen Company) может иметь всего 41 тыс. строк, но эти данные могут быть очень полезны команде специалистов по маркетингу, оценивающей расходы на телевизионную рекламу.
Степень детализации
Подходят ли данные для анализа того уровня, который вам необходим?
Таблица 2. Пример словаря данных из проекта в области здравоохранения в Калифорнии
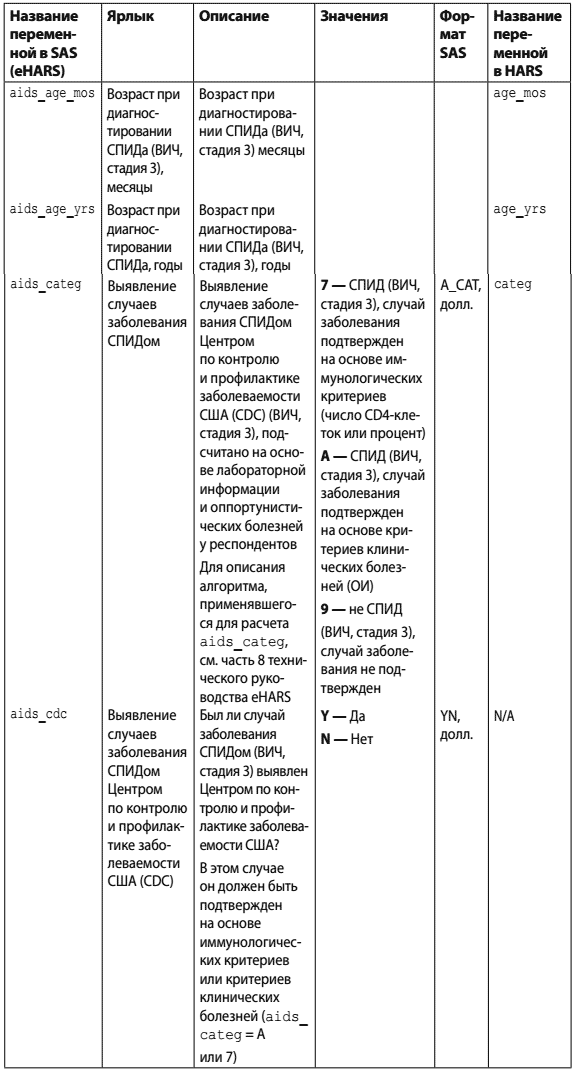
Благодаря качественному словарю становится понятно, как определяются данные, в каком формате и с какими допустимыми значениями. В данном случае также очевидно, как эти данные используются программным обеспечением. Приведены несколько строк из eHARS (Enhanced HIV/AIDS Reporting System — Улучшенная система сбора информации о ВИЧ/СПИДе) в Калифорнии. (SAS — статистический набор приложений, активно применяющийся в области медицины.)
Сколько стоит набор данных?
Посчитать, во сколько вам обходятся данные, относительно легко. Можно проанализировать величину прямых расходов на хранение (например, стоимость услуг Amazon Web Services), стоимость сервисов резервного копирования, зарплаты сотрудников, обеспечивающих хранение и управление данными, а также их непроизводственные расходы, плюс стоимость приобретения данных (если актуально). При этом компания с управлением на основе данных должна определить ценность этих данных для бизнеса. Какова их ROI? А вот это уже не так просто.
Д’Алессандро и др.7 предложили фреймворк, позволяющий оценить прямую рентабельность инвестиций ROI в долларах, по крайней мере в определенных ситуациях. Они работают в сфере рекламы и разработали прогнозные модели для вычисления, какие рекламные объявления эффективнее всего показывать каждому пользователю. Они получают деньги только за переход пользователя по рекламному объявлению. При этом сценарии результат и выручка очевидны: они получают, скажем, 1 долл., если пользователь переходит по рекламному объявлению, и 0 долл., если пользователь ничего не делает. У них есть собственный набор данных, на основании которых они строят свои модели. Некоторые из них — ретроспективные, взятые на основе действовавших ранее цен, а некоторые были ими приобретены в прошлом (их относят к категории невозвратных затрат). Вопрос, которым они руководствуются: «Какова рентабельность моделей, построенных на наших собственных данных, по сравнению с моделями, построенными на данных от третьих лиц?» Для этого требуется определить три компонента:
- какова стоимость действия (в данном случае действие — это переход пользователя, его стоимость — 1 долл.);
- какова ожидаемая стоимость модели на основе наших собственных данных;
- какова ожидаемая стоимость модели на основе наших данных и дополнительных данных третьей стороны.
Итого:
Стоимость данных = ожидаемая стоимость (модель на основе данных третьей стороны) - ожидаемая стоимость (модель без использования данных третьей стороны)
и
Предельная норма прибыли = стоимость (переход) х стоимость данных.
Предположим, у модели на основе собственных данных всего 1% вероятности, что по рекламному объявлению будет переход, а у модели на основе дополнительных данных третьей стороны эта вероятность составляет 5%. Ценность данных выше на 4%, а прирост ценности этих данных составляет 1 долл. х (5% - 1%) = 0,04 долл.
Располагая конкретным значением вроде этого, можно объективно определить целесообразность приобретения этих данных. Если стоимость дополнительных данных 0,04 долл., тогда это нерентабельно. А если их стоимость составит, например, 0,01 долл., решение очевидно. Вы можете не ограничиваться только оценкой прироста ценности данных третьей стороны в дополнение к собственным данным. Когда речь идет о данных, в большинстве случаев самая важная роль отводится контексту. Д’Алессандро и др. провели интересный эксперимент, в ходе которого сравнили прирост ценности данных третьей стороны по сравнению со случайным таргетированием пользователей, то есть полным отсутствием данных по сравнению с данными только третьей стороны. Они получили положительный прирост ценности по целому ряду сегментов: стоимость по сегменту / 1 тыс. пользователей составила 1,8 долл. Затем они повторили эксперимент и использовали собственные данные плюс данные третьей стороны. Как вы думаете, какой результат они получили? Прирост ценности упал! Стоимость по сегменту на 1 тыс. пользователей теперь была около 0,02 долл. В контексте данных, которыми они уже располагали, дополнительные данные обеспечили положительную, но незначительно малую ценность (рис. 2), вероятнее всего, из-за избыточности данных.
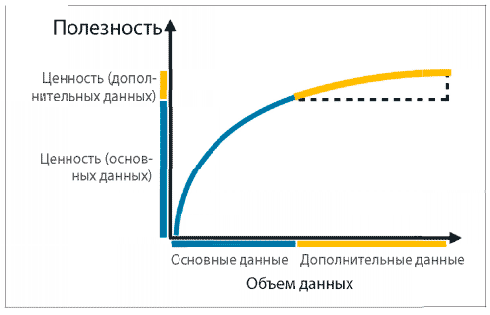
Рис. 2. Дополнительные данные должны способствовать повышению ценности, но наблюдается убывающая доходность
Источник
Этот общий подход достаточно эффективен, так как есть возможность приобрести выборку данных, которую можно протестировать. Если полученный результат хороший, можно приобрести полный набор данных. То есть они не связаны обязательством по приобретению полного набора данных, пока не проведут эксперименты, подтверждающие их ценность. К сожалению, не все поставщики данных и не всегда идут на такие условия. Тем не менее, возможно, вы вносите ежемесячную оплату за пользование данными. В таком случае вы можете проанализировать ценность данных с помощью описанных выше экспериментов и увидеть, насколько рентабельно их использование. Если для вас это нерентабельно, откажитесь от услуг этого поставщика.
Авторы делают заключение:
По мере того как большие данные превращаются в панацею при принятии многих решений по оптимизации бизнеса, для руководителей все большее значение приобретает способность рационально оценить свои решения и инвестиции в приобретение и использование данных. Без инструментов для проведения подобной оценки большие данные становятся скорее интуитивным подходом, чем научной практикой.
Аминь!
Хранение данных
Эта глава была посвящена нахождению и интеграции дополнительных данных. В результате этого процесса увеличивается объем данных, с которыми работают аналитики. При этом данные могут устаревать. Ранее мы уже говорили о стоимости данных — издержках на их приобретение, хранение и управление ими. Кроме того, есть издержки и риски, которые не так легко оценить: какой урон может нанести вашему бизнесу, например, утечка данных? Один из аспектов, о которых следует задуматься, — когда удалять данные (сокращая риск утечки и издержки на хранение) и когда перемещать данные на подходящий носитель для хранения.
У данных есть одна особенность: они множатся. Вы можете загрузить набор данных в реляционную базу, но на этом все не закончится. Ваши данные могут сохраниться в одну или несколько подчиненных баз при неполадках с сервером, на котором хранится основная база данных. И вот у вас уже две копии. Кроме того, вы можете проводить резервное копирование на сервер. Обычно таких резервных копий, на случай, если что-то пойдет не так, у вас может быть за несколько дней, даже за неделю. Так что вы теперь обладатель девяти копий, и хранение каждой из них стоит денег. Как поступить в такой ситуации? Один из вариантов — сопоставлять наборы данных с адекватным периодом ожидания, в течение которого их можно использовать или сохранить.
Рассмотрим такой пример: Amazon S3 — дешевый и простой способ хранения данных1. Хранение данных с помощью такого сервиса определенно обойдется дешевле, чем покупка и обслуживание дополнительного сервера для хранения резервных копий. Получить данные вы можете в любой момент, когда они вам потребуются. При этом Amazon также предлагает похожий сервис под названием glacier. По сути, он очень похож на S3, но создавался как сервис для архивного хранения данных, и на получение данных может уйти четыре-пять часов. При текущем уровне цен стоимость glacier в три раза ниже, чем S3. В случае экстренной ситуации потребуются ли вам данные немедленно или вы сможете обойтись без них полдня или день?
Компании с управлением на основе данных следует тщательно оценить их стоимость. Изначально сосредоточиться нужно на основных данных, где любой простой может иметь серьезные последствия.
Компании следует наладить процесс удаления устаревших данных (это бывает легче сказать, чем сделать) или, в крайнем случае, хотя бы перемещать эти данные на самые дешевые из возможных источников хранения.
Более эффективные компании с управлением на основе данных, например достигшие уровня прогнозного моделирования, могут разрабатывать модели, которые используют только самые необходимые данные и отбрасывают все остальные. Например, по словам Майкла Ховарда, CEO компании С9, «отдел продаж не хранит детали заказа более 90 дней». Если это так, то необходимо тщательно отбирать данные. Как мы показали, компании с управлением на основе данных следует стратегически подходить к выбору источников данных и к ресурсам компании на работу с данными. Аналитики выполняют важные функции по анализу потенциальных источников информации и поставщиков данных, по приобретению выборок и, по возможности, по оценке качества данных и применению выборки для определения ценности данных.
1 Чарльз Бэббидж (1791-1871) — английский математик, изобретатель первой аналитической вычислительной машины. Прим. перев.
2 Тим Бернерс-Ли (р. 1955) — британский ученый, создатель Всемирной паутины. Автор множества разработок в области информационных технологий. Прим. перев.
4 Anderson C. The Long Tail: Why the Future of Business Is Selling Less of More. New York: Hachette Books, 2005. Издана на русском языке: Андерсон К. Длинный хвост. Эффективная модель бизнеса в Интернете. М. : Манн, Иванов и Фербер, 2012. Прим. ред.
5 Fortuny E. J. de, Martens D. and Provost F. Predictive Modeling with Big Data: Is Bigger Really Better? Big Data 1, no. 4 (2013): 215-226.
6 Впервые встречается у Д. Лейни. 3D Data Management: Controlling Data Volume, Velocity and Variety. Application Delivery Strategies by META Group Inc., February 6, 2001.
7 d’Alessandro B., Perlich C. and Raeder T. Bigger is Better, But At What Cost? Big Data 2, no. 2 (2014): 87-96.
