Работа с Big Data: основные области и возможности
По материалам research&trends
Big Data, «Большие данные» вот уже несколько лет как стали притчей во языцех в IT-и маркетинговой прессе. И понятно: цифровые технологии пронизали жизнь современного человека, «все пишется». Объем данных о самых разных сторонах жизни растет, и одновременно растут возможности хранения информации.
Глобальные технологии для хранения информации

Источник: Hilbert and Lopez, `The world's technological capacity to store, communicate, and compute information,`Science, 2011 Global.
Большинство экспертов сходятся во мнении, что ускорение роста объема данных является объективной реальностью. Социальные сети, мобильные устройства, данные с измерительных устройств, бизнес-информация – вот лишь несколько видов источников, способных генерировать гигантские объемы информации. По данным исследования IDC Digital Universe , опубликованного в 2012 году, ближайшие 8 лет количество данных в мире достигнет 40 Зб (zettabytes) что эквивалентно 5200 Гб на каждого жителя планеты.
Рост собираемой цифровой информации в США
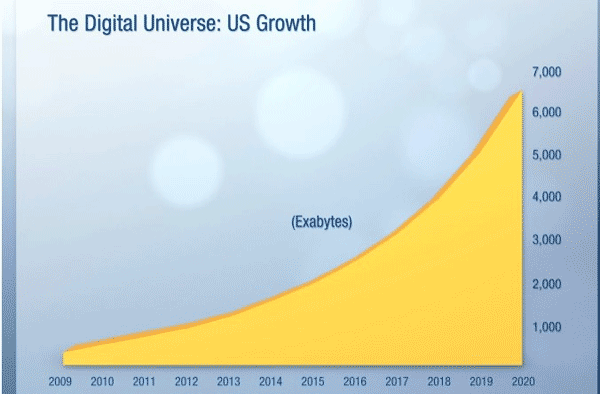
Источник: IDC
Значительную часть информации создают не люди, а роботы, взаимодействующие как друг с другом, так и с другими сетями данных – такие, как, например, сенсоры и интеллектуальные устройства. При таких темпах роста количество данных в мире, по прогнозам исследователей, будет ежегодно удваиваться. Количество виртуальных и физических серверов в мире вырастет десятикратно за счет расширения и создания новых data-центров. В связи с этим растет потребность в эффективном использовании и монетизации этих данных. Поскольку использование Big Data в бизнесе требует немалых инвестиций, то надо ясно понимать ситуацию. А она, в сущности, проста: повысить эффективность бизнеса можно сокращая расходы или/и увеличивая объем продаж.
Для чего нужны Big Data
Парадигма Big Data определяет три основных типа задач.
- Хранение и управление объемом данных в сотни терабайт или петабайт, которые обычные реляционные базы данных не позволяют эффективно использовать.
- Организация неструктурированной информации, состоящей из текстов, изображений, видео и других типов данных.
- Анализ Big Data, который ставит вопрос о способах работы с неструктурированной информацией, генерацию аналитических отчетов, а также внедрение прогностических моделей.
Рынок проектов Big Data пересекается с рынком бизнес-аналитики (BA), объем которого в мире, по оценкам экспертов, в 2012 году составил около 100 млрд. долларов. Он включает в себя компоненты сетевых технологий, серверов, программного обеспечения и технических услуг.
Также использование технологий Big Data актуально для решений класса гарантирования доходов (RA), предназначенных для автоматизации деятельности компаний. Современные системы гарантирования доходов включают в себя инструменты обнаружения несоответствий и углубленного анализа данных, позволяющие своевременно обнаружить возможные потери, либо искажение информации, способные привести к снижению финансовых результатов. На этом фоне российские компании, подтверждающие наличие спроса технологий Big Data на отечественном рынке, отмечают, что факторами, которые стимулируют развитие Big Data в России, являются рост данных, ускорение принятия управленческих решений и повышение их качества.
Что мешает работать с Big Data
Сегодня анализируется только 0,5% накопленных цифровых данных, несмотря на то, что объективно существуют общеотраслевые задачи, которые можно было бы решить с помощью аналитических решений класса Big Data. Развитые IT-рынки уже имеют результаты, по которым можно оценить ожидания, связанные с накоплением и обработкой больших данных.
Одним из главных факторов, который тормозит внедрение Big Data - проектов, помимо высокой стоимости, считается проблема выбора обрабатываемых данных : то есть определение того, какие данные необходимо извлекать, хранить и анализировать, а какие – не принимать во внимание.
Многие представители бизнеса отмечают, что сложности при внедрении Big Data-проектов связаны с нехваткой специалистов – маркетологов и аналитиков. От качества работы сотрудников, занимающихся глубинной и предикативной аналитикой, напрямую зависит скорость возврата инвестиций в Big Data. Огромный потенциал уже существующих в организации данных часто не может быть эффективно использован самими маркетологами из-за устаревших бизнес-процессов или внутренних регламентов. Поэтому часто проекты Big Data воспринимаются бизнесом как сложные не только в реализации, но и в оценке результатов: ценности собранных данных. Специфика работы с данными требует от маркетологов и аналитиков переключения внимания с технологий и создания отчетов на решение конкретных бизнес-задач.
В связи с большим объемом и высокой скоростью потока данных, процесс их сбора предполагает процедуры ETL в режиме реального времени. Для справки: ETL – от англ. Extract, Transform, Load — дословно «извлечение, преобразование, загрузка») — один из основных процессов в управлении хранилищами данных, который включает в себя: извлечение данных из внешних источников, их трансформацию и очистку с целью соответствия нуждам бизнес-модели и загрузка их в хранилище данных. ETL следует рассматривать не только как процесс переноса данных из одного приложения в другое, но и как инструмент подготовки данных к анализу.
И тогда вопросы обеспечения безопасности данных, поступающих из внешних источников, должны иметь решения, соответствующие объемам собираемой информации. Так как методы анализа Big Data развиваются пока только вслед за ростом объема данных, большую роль играет свойство аналитических платформ использовать новые методы подготовки и агрегирования данных. Это говорит о том, что, например, данные о потенциальных покупателях или массивное хранилище данных с историей кликов на сайтах online-магазинов могут быть интересны для решения разных задач.
Трудности не останавливают
Несмотря на все сложности с внедрением Big Data, бизнес намерен увеличивать вложения в это направление. Как следует из данных Gartner, в 2013 году 64% крупнейших мировых компаний уже инвестировали, либо имеют планы инвестировать в развертывание технологий в области Big Data для своего бизнеса, тогда, как в 2012 году таких было 58%. По данным исследования Gartner, лидерами инвестирующих в Big Data отраслей являются медиа компании, телеком, банковский сектор и сервисные компании. Успешные результаты внедрения Big Data уже достигнуты многими крупными игроками в сфере розничной торговли в части использования данных, полученных с помощью инструментов радиочастотной идентификации, систем логистики и репленишмента (от англ. replenishment - накопление, пополнение – R&T), а также из программ лояльности. Удачный опыт ритейла стимулирует другие отрасли рынка находить новые эффективные способы монетизации больших данных, чтобы превратить их анализ в ресурс, работающий на развитие бизнеса. Благодаря этому, по прогнозам экспертов, в период до 2020 года инвестиции в управление, хранение снизятся на каждый гигабайт данных с 2$ до 0,2$, а вот на изучение и анализ технологических свойств Big Data вырастут всего на 40%.
Расходы, представленные в различных инвестиционных проектах в области Big Data, имеют разный характер. Статьи затрат зависят от видов продуктов, которые выбираются, исходя из определенных решений. Наибольшая часть затрат в инвестиционных проектах, по мнению специалистов, приходится на продукты, связанные со сбором, структурированием данных, очисткой и управлением информацией.
Как это делается
Существует множество комбинаций программного и аппаратного обеспечения, которые позволяют создавать эффективные решения Big Data для различных бизнес дисциплин: от социальных медиа и мобильных приложений, до интеллектуального анализа и визуализации коммерческих данных. Важное достоинство Big Data – это совместимость новых инструментов с широко используемыми в бизнесе базами данных, что особенно важно при работе с кросс-дисциплинарными проектами, например, такими как организация мульти-канальных продаж и поддержки покупателей.
Последовательность работы с Big Data состоит из сбора данных, структурирования полученной информации с помощью отчетов и дашбордов (dashboard), создания инсайтов и контекстов, а также формулирования рекомендаций к действию. Так как работа с Big Data подразумевает большие затраты на сбор данных, результат обработки которых заранее неизвестен, основной задачей является четкое понимание, для чего нужны данные, а не то, как много их есть в наличии. В этом случае сбор данных превращается в процесс получения исключительно нужной для решения конкретных задач информации.
Например, у телекоммуникационных провайдеров агрегируется огромное количество данных, в том числе о геолокации, которые постоянно пополняются. Эта информация может представлять коммерческий интерес для рекламных агентств, которые могут использовать ее для показа таргетированной и локальной рекламы, а также для ритейлеров и банков. Подобные данные могут сыграть важную роль при решении открытия торговой точки в определенной локации на основе данных о наличии мощного целевого потока людей. Есть пример измерения эффективности рекламы на outdoor-щитах в Лондоне. Сейчас охват подобной рекламы можно измерить лишь поставив возле рекламных конструкций людей со специальным устройством, подсчитывающим прохожих. По сравнению с таким видом измерения эффективности рекламы, у мобильного оператора куда больше возможностей – он точно знает местонахождение своих абонентов, ему известны их демографические характеристики, пол, возраст, семейное положение, и т.д.
На основе таких данных, в будущем открывается перспектива менять содержание рекламного сообщения, используя предпочтения конкретного человека, проходящего мимо рекламного щита. Если данные показывают, что проходящий мимо человек много путешествует, то ему можно будет показать рекламу курорта. Организаторы футбольного матча могут оценить количество болельщиков только когда те придут на матч. Но если бы они имели возможность запросить у оператора сотовой связи информацию, где посетители находились за час, день или месяц до матча, то это дало бы организаторам возможность планировать места для размещения рекламы следующих матчей.
Другой пример – как банки могут использовать Big Data для предотвращения мошенничества. Если клиент заявляет об утере карты, а при совершении покупки с ее помощью банк видит в режиме реального времени месторасположение телефона клиента в зоне покупки, где происходит транзакция, банк может проверить информацию по заявлению клиента, не пытался ли он обмануть его. Либо противоположная ситуация, когда клиент совершает покупку в магазине, банк видит, что карта, по которой происходит транзакция, и телефон клиента находятся в одном месте, банк может сделать вывод, что картой пользуется ее владелец. Благодаря подобным преимуществам Big Data, расширяются границы, которыми наделены традиционные хранилища данных.
Для успешного принятия решения о внедрении решений Big Data компании необходимо рассчитать инвестиционный кейс и это вызывает большие трудности из-за множества неизвестных составляющих. Парадоксом аналитики в подобных случаях становится прогнозирование будущего на основе прошлого, данные о котором зачастую отсутствуют. В этом случае важным фактором является четкое планирование своих первоначальных действий:
- Во-первых, необходимо определить одну конкретную задачу бизнеса, для решения которой будут использоваться технологии Big Data, эта задача станет стержнем определения верности выбранной концепции. Необходимо сосредоточиться на сборе данных, связанных именно с этой задачей, а в ходе проверки концепции вы сможете использовать различные инструменты, процессы и методы управления, которые позволят принимать более обоснованные решения в будущем.
- Во-вторых, маловероятно, что компания без навыков и опыта аналитики данных сможет успешно реализовать проект Big Data. Необходимые знания всегда вытекают из предыдущего опыта аналитики, что является основным фактором, влияющим на качество работы с данными. Важную роль играет культура использования данных, так как часто анализ информации открывает суровую правду о бизнесе, и чтобы принять эту правду и работать с ней, необходимы выработанные методы работы с данными.
- В третьих, ценность технологий Big Data заключается в предоставлении инсайтов Хорошие аналитики остаются дефицитом на рынке. Ими принято называть специалистов, имеющих глубокое понимание коммерческого смысла данных и знающих, как правильно их применять. Анализ данных является средством для достижения целей бизнеса, и чтобы понять ценность Big Data, необходима соответствующая модель поведения и понимание своих действий. В этом случае большие данные дадут массу полезной информации о потребителях, на основе которой можно принять полезные для бизнеса решения.
Несмотря на то, что российский рынок Big Data только начинает формироваться, отдельные проекты в этой области уже реализуются достаточно успешно. Некоторые из них успешны в области сбора данных как, например, проекты для ФНС и банка «Тинькофф Кредитные Системы», другие - в части анализа данных и практического применения его результатов: это проект Synqera.
В банке «Тинькофф Кредитные Системы» был реализован проект по внедрению платформы EMC2 Greenplum, которая является инструментом для массивно-параллельных вычислений. В течение последних лет у банка выросли требования к скорости обработки накопленной информации и анализа данных в режиме реального времени, вызванные высокими темпами роста количества пользователей кредитных карт. Банк объявил о планах расширения использования технологий Big Data, в частности для обработки неструктурированных данных и работы с корпоративной информацией, получаемой из разных источников.
В ФНС России в настоящий момент идет создание аналитического слоя федерального хранилища данных. На его основе создается единое информационное пространство и технология доступа к налоговым данным для статистической и аналитической обработки. В ходе реализации проекта выполняются работы по централизации аналитической информации с более чем 1200 источниками местного уровня ИФНС.
Еще одним интересным примером анализа больших данных в режиме реального времени является российский стартап Synqera, который разработал платформу Simplate. Решение основано на обработке больших массивов данных, программа анализирует информацию о покупателях, историю их покупок, возраст, пол и даже настроение. На кассах в сети косметических магазинов были установлены сенсорные экраны с датчиками, распознающими эмоции покупателей. Программа определяет настроение человека, анализирует информацию о нем, определяет время суток и сканирует базу скидок магазина, после чего отправляет покупателю таргетированные сообщения об акциях и специальных предложениях. Это решение повышает покупательскую лояльность и увеличивает продажи ритейлеров.
Если говорить об иностранных успешных кейсах, то в этом плане интересен опыт применения технологий Big Data в компании Dunkin`Donuts, использующей данные в режиме реального времени для продажи продукции. Цифровые дисплеи в магазинах отображают предложения, сменяющие друг друга каждую минуту, в зависимости от времени суток и наличия продукции. По кассовым чекам компания получает данные, какие именно предложения получили наибольший отклик у покупателей. Данный подход обработки данных позволил увеличить прибыль и оборачиваемость товаров на складе.
Как показывает опыт внедрения Big Data-проектов, эта область призвана успешно решать современные бизнес-задачи. При этом важным фактором достижения коммерческих целей при работе с большими данными является выбор правильной стратегии, которая включает в себя аналитику, выявляющую запросы потребителей, а также использование инновационных технологий в области Big Data.
По данным глобального опроса, ежегодно проводимого Econsultancy и Adobe с 2012 года среди маркетологов компаний, «большие данные», характеризующие действия людей в Интернете, могут многое. Они способны оптимизировать оффлайновые бизнес-процессы, помочь понять как владельцы мобильных девайсов пользуются ими для поиска информации или просто «сделать маркетинг лучше», т.е. эффективнее. Причем, последняя функция год от года все популярнее, как это следует из приведенной нами диаграммы.
Основные области работы интернет-маркетологов с точки зрения отношений с покупателями
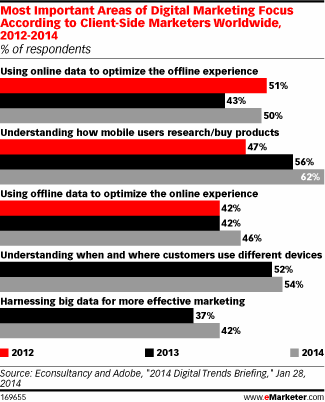
Источник: Econsultancy and Adobe, опубликовано – emarketer.com
Заметим, что национальность респондентов большого значения не имеет. Как показывает опрос, проведенный KPMG в 2013 году, доля «оптимистов», т.е. тех, кто использует Big Data при разработке бизнес-стратегии, составляет 56%, причем, колебания от региона к региону невелики: от 63% в североамериканских странах до 50% в EMEA.
Использование Big Data в различных регионах мира
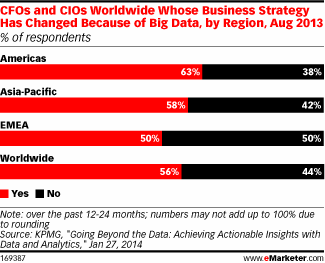
Источник: KPMG, опубликовано – emarketer.com
Между тем, отношение маркетологов к подобным «модным трендам» в чем-то напоминает известный анекдот:
- Скажи, Вано, ты помидоры любишь?
- Поесть люблю, а так – нет.
Несмотря на то, что маркетологи на словах «любят» Big Data и вроде бы даже их используют, на самом деле, «все сложно», как пишут о своих сердечных привязанностях в соцсетях.
По данным опроса, проведенного компанией Circle Research в январе 2014 года среди европейских маркетологов, 4 из 5 опрошенных не используют Big Data (при том, что они их, конечно, «любят»). Причины разные. Закоренелых скептиков немного – 17% и ровно столько же, сколько и их антиподов, т.е. тех, кто уверенно отвечает: «Да». Остальные – это колеблющиеся и сомневающиеся, «болото». Они уходят от прямого ответа под благовидными предлогами в духе того, что «пока нет, но скоро» или «подождем, пока остальные начнут».
Использование Big Data маркетологами, Европа, январь 2014
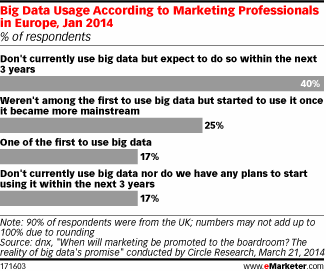
Источник: dnx, опубликовано – emarketer.com
Что же их смущает? Сущие пустяки. Некоторые (их ровно половина) попросту не верят этим данным. Другие (их тоже немало – 55%) затрудняются в соотнесении между собой множеств «данных» и «пользователей». У кого-то просто (выразимся политкорректно) внутрикорпоративный беспорядок: данные бесхозно гуляют между маркетинговыми отделами и IT структурами. У других софт не справляется с наплывом работы. И так далее. Поскольку суммарные доли существенно превышают 100%, понятно, что ситуация «множественных барьеров» встречается нередко.
Барьеры, препятствующие использованию Big Data в маркетинге
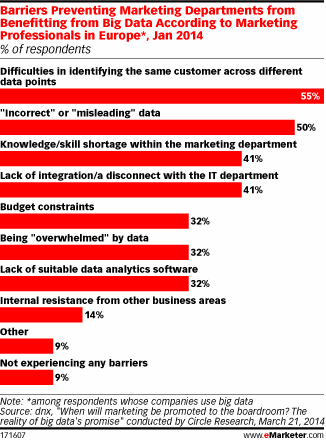
Источник: dnx, опубликовано – emarketer.com
Таким образом, приходится констатировать, что пока «Большие данные» - это большой потенциал, которым еще надо суметь воспользоваться. Кстати говоря, именно это может быть и стало причиной того, что Big Data утрачивают ореол «модного тренда», как об этом свидетельствуют данные опроса, проведенного уже упомянутой нами компании Econsultancy.
Самые значимые тренды в диджитал-маркетинге 2013-2014
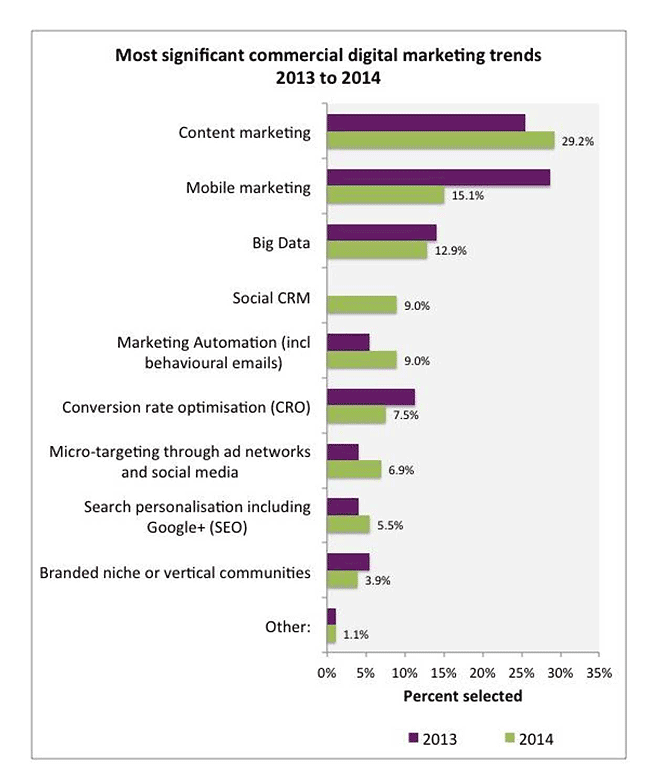
Источник: Econsultancy and Adobe
На смену им выходит другой король – контент-маркетинг. Надолго ли?
Нельзя сказать, что Большие Данные – это какое-то принципиально новое явление. Большие источники данных существуют уже много лет: базы данных по покупкам клиентов, кредитным историям, образу жизни. И в течение многих лет ученые использовали эти данные, чтобы помогать компаниям оценивать риск и прогнозировать будущие потребности клиентов. Однако сегодня ситуация изменилась в двух аспектах:
- появились более сложные инструменты и методы для анализа и сочетания различных наборов данных;
- эти аналитические инструменты дополнены целой лавиной новых источников данных, вызванной переходом на цифровые технологии практически всех методов сбора и измерения данных.
Диапазон доступной информации одновременно и вдохновляет, и пугает исследователей, выросших в структурированной исследовательской среде. Потребительские настроения фиксируются сайтами и всевозможными разновидностями социальных медиа. Факт просмотра рекламы фиксируется не только телевизионными приставками, но и с помощью цифровых тегов и мобильных устройств, общающихся с телевизором.
Поведенческие данные (такие как число звонков, покупательские привычки и покупки) теперь доступны в режиме реального времени. Таким образом, многое из того, что раньше можно было получить с помощью исследований, сегодня можно узнать с помощью источников больших данных. И все эти информационные активы генерируются постоянно, независимо от каких бы то ни было исследовательских процессов. Эти изменения и заставляют нас задаться вопросом: смогут ли большие данные заменить собой классические исследования рынка.
Дело не в данных, дело в вопросах и ответах
Прежде чем заказывать похоронный звон по классическим исследованиям, мы должны напомнить себе, что решающее значение имеет не наличие тех или иных активов данных, а нечто иное. Что именно? Наша способность отвечать на вопросы, вот что. У нового мира больших данных есть одна забавная черта: результаты, полученные на основе новых информационных активов, приводят к появлению еще большего количества вопросов, а на эти вопросы, как правило, лучше всего отвечают традиционные исследования. Таким образом, по мере роста больших данных мы видим параллельный рост наличия и потребности в «маленьких данных» (small data), которые могут дать ответы на вопросы из мира больших данных.
Рассмотрим ситуацию: крупный рекламодатель проводит постоянный мониторинг трафика в магазинах и объемов продаж в режиме реального времени. Существующие исследовательские методики (в рамках которых мы опрашиваем участников исследовательских панелей об их мотивациях к покупке и поведении в точках продаж) помогают нам лучше нацелиться на определенные сегменты покупателей. Эти методики могут быть расширены – они могут включать в себя более широкий диапазон активов больших данных вплоть до того, что большие данные становятся средством пассивного наблюдения, а исследования – методом постоянного узкоцелевого исследования изменений или событий, требующих изучения. Именно так большие данные могут освободить исследования от лишней рутины. Первичные исследования уже не должны фокусироваться на том, что происходит (это сделают большие данные). Вместо этого первичные исследования могут сосредоточиться на объяснении того, почему мы наблюдаем те или иные тенденции или отклонения от тенденций. Исследователь сможет меньше думать о получении данных, и больше – о том, как их проанализировать и использовать.
В то же время мы видим, что большие данные позволяют решать одну из наших самых больших проблем – проблему чрезмерно длинных исследований. Изучение самих исследований показало, что чрезмерно раздутые исследовательские инструменты оказывают негативное воздействие на качество данных. Хотя многие специалисты в течение длительного времени признавали наличие этой проблемы, они неизменно отвечали на это фразой: «Но ведь эта информация нужна мне для высшего руководства», и длинные опросы продолжались.
В мире больших данных, где количественные показатели можно получить с помощью пассивного наблюдения, этот вопрос становится спорным. Опять же, давайте вспомним обо всех этих исследованиях, касающихся потребления. Если большие данные дают нам инсайты о потреблении с помощью пассивного наблюдения, то первичным исследованиям в форме опросов уже не надо собирать такого рода информацию, и мы сможем, наконец, подкрепить свое видение коротких опросов не только благими пожеланиями, но и чем-то реальным.
Big Data нуждаются в вашей помощи
Наконец, «большие» - это лишь одна из характеристик больших данных. Характеристика «большие» относится к размеру и масштабу данных. Конечно, это основная характеристика, поскольку объем этих данных выходит за рамки всего того, с чем мы работали прежде. Но другие характеристики этих новых потоков данных также важны: они зачастую плохо форматированы, неструктурированны (или, в лучшем случае, структурированы частично) и полны неопределенности. Развивающаяся область управления данными, метко названная «анализ сущностей» (entity analytics), призвана решить проблему преодоления шума в больших данных. Ее задача – проанализировать эти наборы данных и выяснить, сколько наблюдений относится к одному и тому же человеку, какие наблюдения являются текущими, и какие из них – пригодны для использования.
Такой вид очистки данных необходим для того, чтобы удалить шум или ошибочные данные при работе с активами больших или небольших данных, но этого недостаточно. Мы также должны создать контекст вокруг активов больших данных на основе нашего предыдущего опыта, аналитики и знания категории. На самом деле, многие аналитики указывают на способность управлять неопределенностью, присущей большим данным, как источник конкурентного преимущества, так как она позволяет принимать более эффективные решения.
И вот тут-то первичные исследования не только оказываются освобожденными от рутины благодаря большим данным, но и вносят свой вклад в создание контента и анализ в рамках больших данных.
Ярким примером этого может служить приложение нашей новой принципиально иной рамочной модели капитала бренда к социальным медиа (речь идет о разработанном в Millward Brown новом подходе к измерению ценности бренда The Meaningfully Different Framework – «Парадигма значимых отличий» - R&T). Эта модель проверена на поведении в рамках конкретных рынков, реализована на стандартной основе, и ее легко применить в других маркетинговых направлениях и информационных системах для поддержки принятия решений. Другими словами, наша модель капитала бренда, опирающаяся на исследования методом опросов (хотя и не только на них) обладает всеми свойствами, необходимыми для преодоления неструктурированного, несвязного и неопределенного характера больших данных.
Рассмотрим данные по потребительским настроениям, предоставляемые социальными медиа. В сыром виде пики и спады потребительских настроений очень часто минимально коррелируют с параметрами капитала бренда и поведения, полученными в оффлайне: в данных просто слишком много шума. Но мы можем уменьшить этот шум, применяя наши модели потребительского смысла, дифференциации брендов, динамики и отличительных черт к сырым данным потребительских настроений – это способ обработки и агрегации данных социальных медиа по этим измерениям.
После того, как данные организованы в соответствии с нашей рамочной моделью, выявленные тренды обычно совпадают с параметрами капитала бренда и поведения, полученными в оффлайне. По сути, данные социальных медиа не могут говорить сами за себя. Чтобы использовать их для указанной цели требуется наш опыт и модели, выстроенные вокруг брендов. Когда социальные медиа дают нам уникальную информацию, выраженную на том языке, который потребители используют для описания брендов, мы должны использовать этот язык при создании своих исследований, чтобы сделать первичные исследования гораздо более эффективными.
Преимущества освобожденных исследований
Это возвращает нас к тому, что большие данные не столько заменяют исследования, сколько освобождают их. Исследователи будут освобождены от необходимости создавать новое исследование по каждому новому случаю. Постоянно растущие активы больших данных могут быть использованы для разных тем исследований, что позволяет последующим первичным исследованиям углубиться в тему и заполнить имеющиеся пробелы. Исследователи будут освобождены от необходимости полагаться на чрезмерно раздутые опросы. Вместо этого они смогут использовать краткие опросы и сосредоточиться на самых важных параметрах, что повышает качество данных.
Благодаря такому освобождению исследователи смогут использовать свои отработанные принципы и идеи, чтобы добавить точности и смысла активам больших данных, что приведет к появлению новых областей для исследований методом опроса. Этот цикл должен привести к более глубокому пониманию по целому ряду стратегических вопросов и, в конечном счете, к движению в сторону того, что всегда должно быть нашей главной целью - информировать и улучшать качество решений, касающихся бренда и коммуникаций.
