Учебник "Маркетинговые исследования"
Соколова М.И., Гречков В.Ю.
Содержание
- Глава 1: Маркетинговые исследования
- Глава 2: Некоторые основные положения математической статистики
- Глава 3: Использование программы статистической обработки SPSS (v8.0) при анализе результатов маркетинговых исследований
- Приложение 1: Опросный лист (пример)
- Приложение 2: Терминология, используемая в программе SPSS
Глава 2. Некоторые основные положения математической статистики
2.1. Статистические переменные
Под переменными при обработке результатов маркетинговых исследований будем понимать то, что можно измерять, контролировать или изменять.
При исследовании статистических закономерностей принято различать зависимые и независимые переменные. Независимыми переменными в экспериментальном исследовании называются переменные, которые варьируются исследователем, тогда как зависимые переменные - это переменные, которые измеряются или регистрируются. Применительно к маркетинговым исследованиям, независимые переменные не варьируются, а позволяют исследователю разделять объект исследования на некоторые группы. Например, если изучается реакция на новый товар отдельно мужчин и женщин, то при статистической обработке результатов переменная ПОЛ может считаться независимой, а переменная РЕАКЦИЯ НА ТОВАР (выраженная, например, в баллах оценочной шкалы) - зависимой.
Важное значение имеет также шкала измерения переменной. В математической статистике различают следующие типы шкал:
Номинальная шкала. Номинальные переменные используются только для качественной классификации. Это означает, что данные переменные могут быть измерены только в терминах принадлежности к некоторым, существенно различным классам; при этом исследователь не может определить количество или упорядочить эти классы. Например, можно сказать, что 2 опрошенных потребителя принадлежат к разным национальностям. Типичные примеры номинальных переменных - пол, национальность, цвет, город и т.д. Часто номинальные переменные называют категориальными.
Порядковая шкала. Порядковые переменные позволяют ранжировать (упорядочить) объекты, указав какие из них в большей или меньшей степени обладают качеством, выраженным данной переменной. Однако они не позволяют сказать "на сколько больше" или "на сколько меньше". Типичный пример порядковой переменной - уровень дохода опрашиваемого потребителя (при предложенных вариантах ответа: низкий, ниже среднего, средний, выше среднего, высокий, очень высокий). Исследователь понимает, что верхний уровень выше среднего уровня, однако сделать вывод, что разница между ними равна, например, 10% он не сможет. Само расположение шкал в следующем порядке: номинальная, порядковая, интервальная является хорошим примером порядковой шкалы. Порядковые переменные иногда называют ординарными.
Интервальная шкала. Интервальные переменные позволяют не только упорядочивать объекты измерения, но и численно выразить и сравнить различия между ними. Стандартный пример интервальной шкалы - температура, измеренная в градусах Фаренгейта или Цельсия. Исследователь может не только сказать, что температура 40 градусов выше, чем температура 30 градусов, но и что увеличение температуры с 20 до 40 градусов вдвое больше увеличения температуры от 30 до 40 градусов.
Относительная шкала. Относительные переменные похожи на интервальные переменные, но дополнительно ко всем свойствам интервальных переменных, их характерной чертой является наличие определенной точки абсолютного нуля. Типичными примерами шкал отношений являются измерения времени или пространства. Например, температура по Кельвину образует шкалу отношения, и можно не только утверждать, что температура 200 градусов выше, чем 100 градусов, но и что она вдвое выше. Интервальные шкалы (например, шкала Цельсия) не обладают данным свойством шкалы отношения. Известно, что в большинстве статистических процедур не делается различия между свойствами интервальных шкал и шкал отношения.
2.2. Связи и зависимости между переменными
Основной целью при оценке результатов маркетингового исследования является нахождение зависимостей между переменными, определение каких-либо новых взаимосвязей. Статистические методы помогают в поиске таких зависимостей, позволяют их математически оценить. В математической статистике выделяют две основные черты каждой зависимости:
1. Величина. Величину зависимости легче понять и измерить, чем надежность. Например, если по результатам опроса оказалось, что большинство мужчин имеет доход выше среднего, а большинство женщин - ниже среднего, исследователь может сделать вывод, что зависимость между двумя переменными (ПОЛ и УРОВЕНЬ ДОХОДА) высокая.
2. Надежность ("истинность"). Надежность взаимозависимости - менее наглядное понятие, чем величина зависимости, но чрезвычайно важное. Надежность зависимости непосредственно связана с репрезентативностью (представительностью) выборки, на основе которой строятся выводы. Надежность показывает, насколько вероятно, что зависимость, подобная найденной, подтвердится на данных другой выборки, извлеченной из той же самой генеральной совокупности. Как правило, при проведении исследований конечной целью почти никогда не является изучение какой-либо конкретной выборки; исследователя интересуют данные о всей генеральной совокупности (например, о всех потребителях). Если исследование удовлетворяет определенным критериям, то надежность найденных зависимостей между переменными выборки можно количественно оценить и представить с помощью стандартной статистической меры (называемой p-уровень или статистический уровень значимости).
Статистический уровень значимости представляет собой оцененную меру уверенности в том, что полученные результаты "истинны" для всей генеральной совокупности (т.е. исследуемая выборка репрезентативна). В терминах математической статистики p-уровень - это показатель, находящийся в убывающей зависимости от надежности результата: более высокий p-уровень соответствует более низкому уровню доверия к найденной в выборке зависимости между переменными. Именно, p-уровень представляет собой вероятность ошибки, связанной с распространением наблюдаемого результата на всю генеральную совокупность. Например, p - уровень, равный 0,05 показывает, что имеется 5%-ная вероятность, что найденная в выборке связь между переменными является лишь случайной особенностью данной выборки. В маркетинговых исследованиях p-уровень 0,05 часто рассматривается как "приемлемая граница" уровня ошибки.
Необходимо отметить, что выбор определенного уровня значимости, выше которого результаты отвергаются как ложные, является достаточно произвольным. На практике обычно уровень 0,05 является приемлемой границей статистической значимости, однако следует помнить, что этот уровень означает довольно большую вероятность ошибки (5%). Результаты с уровнем значимости 0,01 обычно рассматриваются как статистически значимые, а результаты с уровнем 0,005 или 0,001 как высоко значимые. При этом данная классификация уровней значимости абсолютно произвольна и основана лишь на результатах практического опыта в той или иной области исследований.
Важным вопросом при проведении исследований является величина выборки. Объективно понятно, что размеры выборки связаны с величиной зависимости между переменными: если связь между переменными слабая, то для проверки существования зависимости необходимо исследовать выборку достаточно большого объема. Соответственно, если зависимость "объективно" (в генеральной совокупности) очень сильная, тогда она может быть обнаружена с высокой степенью значимости даже на маленькой выборке. На практике при проведении, например, опросов потребителей, ограничиваются размерами выборки в 1000 - 1500 чел., считая такую выборку достаточно значимой. При проведении анализа результатов опроса потребителей используются ряд статистических критериев (которые будут рассмотрены ниже в данной главе) для подтверждения того, что полученные на такой выборке результаты можно распространить на всю генеральную совокупность.
В математической статистике существует много различных мер взаимосвязи между переменными. Выбор определенной меры в конкретном исследовании зависит от числа переменных, используемых шкал измерения, природы зависимостей и т.д. Большинство этих мер, тем не менее, подчиняются общему принципу: они пытаются оценить наблюдаемую зависимость, сравнивая ее с "максимальной возможной зависимостью" между рассматриваемыми переменными. Обычный способ выполнить такие оценки заключается в том, чтобы посмотреть как варьируются значения переменных и затем подсчитать, какую часть всей имеющейся вариации можно объяснить наличием "общей" ("совместной") вариации двух (или более) переменных. Иначе говоря, сравнивается то "что есть общего в этих переменных", с тем "что потенциально было бы у них общего, если бы переменные были абсолютно зависимы". Так как конечная цель большинства статистических критериев состоит в оценивании зависимости между переменными, большинство из них основано на этом общем принципе. В терминах математической статистики, эти критерии представляют собой отношение изменчивости, общей для рассматриваемых переменных, к полной изменчивости. Это отношение обычно называется отношением объясненной вариации к полной вариации (термин "объясненная вариация" не обязательно означает, что ей дается какое-либо теоретическое объяснение - он используется только для обозначения общей вариации рассматриваемых переменных, т.е. для указания на то, что часть вариации одной переменной "объясняется" определенными значениями другой переменной и наоборот).
В математической статистике используются функции, позволяющие вычислить уровень значимости, и, следовательно, вероятность ошибочно отклонить предположение об отсутствии зависимости в генеральной совокупности. Такая "альтернативная" гипотеза (т.е. утверждение о том, что в генеральной совокупности нет зависимости между переменными) обычно называется нулевой гипотезой. Эти функции можно использовать для определения уровней значимости при исследовании различных выборок. Большинство этих функций связано с очень важным классом распределений, называемым нормальным.
Нормальное распределение - очень важное понятие.
В большинстве случаев оно является хорошим приближением функций, упоминаемых в предыдущем абзаце. Распределение многих статистик является нормальным или может быть получено из нормального с помощью некоторых преобразований. Многие случайные величины в природе имеют нормальное распределение.
Точная форма нормального распределения (характерная "колоколообразная кривая") определяется только двумя параметрами: средним и стандартным отклонением. Характерное свойство нормального распределения состоит в том, что 68% всех его наблюдений лежат в диапазоне ±1 стандартное отклонение от среднего µ, а диапазон ±2 стандартных отклонения содержит 95% значений.

Многие статистические критерии, которые будут рассмотрены в
Рис 2.1. Пример нормального распределения.
дальнейшем, требуют нормального распределения анализируемых переменных. Строго говоря, нельзя применять тесты, основанные на предположении нормальности, к данным, не являющимся нормальными. В этом случае можно использовать альтернативные "непараметрические" тесты, не требующие нормальности распределения исследуемых переменных. Однако это часто неудобно, поскольку обычно эти критерии имеют меньшую мощность и обладают меньшей гибкостью. Как альтернативу, во многих случаях можно все же использовать тесты, основанные на предположении нормальности при достаточно большом объеме выборки.
(Проводились специальные исследования, чтобы оценить, насколько тесты, основанные на предположении нормальности, чувствительны к различным нарушениям этих предположений. Общий вывод этих исследований состоит в том, что последствия нарушения предположения нормальности менее тяжелы, чем первоначально предполагалось. Хотя эти выводы не означают, что предположения нормальности можно игнорировать, они подтверждают возможность более широкого использования на практике тестов, основанных на нормальном распределении).
2.3. Описательные статистики и проверка статистических гипотез.
Самой простой описательной статистикой, многим известной из практики, является среднее значение. Среднее - очень информативная мера "центрального положения" наблюдаемой переменной, особенно если сообщается ее доверительный интервал. Исследователю нужны такие статистики, которые позволяют сделать вывод относительно всей генеральной совокупности (например, всех потребителей). Одной из таких статистик и является среднее. Доверительный интервал для среднего представляет интервал значений вокруг оценки, где с данным уровнем доверия находится среднее генеральной совокупности.
Например, если среднее переменной ВОЗРАСТ РЕСПОНДЕН-ТА равно 40 (лет), а нижняя и верхняя границы доверительного интервала с уровнем 0.95 равны 20 и 60 соответственно, то с вероятностью 95% интервал с границами 20 и 60 накрывает среднее генеральной совокупности (потребителей). Если установить больший уровень доверия, то интервал станет шире, поэтому возрастает вероятность, с которой он "накрывает" неизвестное среднее генеральной совокупности. В общем можно заметить, что ширина доверительного интервала зависит от объема или размера выборки, а также от разброса (изменчивости) данных: увеличение размера выборки делает оценку среднего более надежной, а увеличение разброса наблюдаемых значений, напротив, уменьшает надежность оценки. Важно отметить, что вычисление доверительных интервалов основывается на предположении нормальности наблюдаемых величин. Если это предположение не выполнено, то оценка может оказаться плохой, особенно для малых выборок.
Важным способом описания переменной является форма ее распределения, которая показывает, с какой частотой значения переменной попадают в определенные интервалы, выбираемые исследователем. Обычно исследователя интересует, насколько точно распределение можно аппроксимировать нормальным (рис 2.1). Простые описательные статистики дают об этом некоторую информацию. Существуют два важных показателя вида распределения переменной, позволяющие проверить гипотезу нормальности: асимметрия и эксцесс. Например, если асимметрия (показывающая отклонение распределения от симметричного) существенно отличается от нуля, то распределение несимметрично (нормальное распределение абсолютно симметрично). Асимметрия скошенного вправо распределения положительна, скошенного влево - отрицательна. Эксцесс показывает "остроту пика" распределения, и если он существенно отличен от нуля, то распределение имеет или более закругленный пик, чем нормальное, или, напротив, имеет более острый пик (возможно, имеется несколько пиков). Обычно, если эксцесс положителен, то пик заострен, если отрицательный, то пик закруглен. Эксцесс нормального распределения равен нулю.
Более точную информацию о форме распределения можно получить с помощью критериев нормальности (критерия Колмогорова-Смирнова или критерия Шапиро-Уилкса). Однако ни один из этих критериев не может заменить визуальную проверку статистической гипотезы нормальности с помощью гистограммы (графика, показывающего частоту попаданий значений переменной в отдельные интервалы).
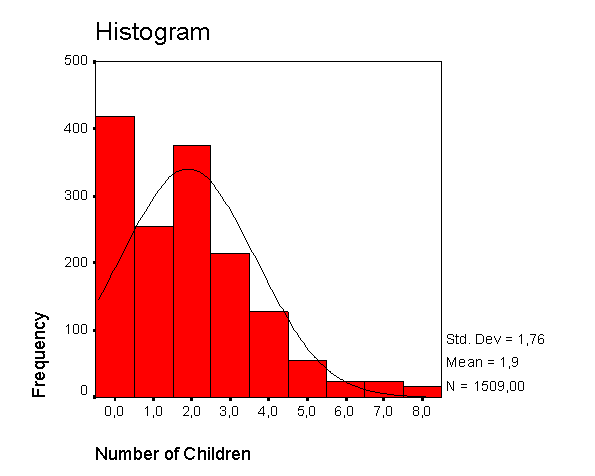
Рис. 2.2. Пример гистограммы распределения переменной
КОЛИЧЕСТВО ДЕТЕЙ
Гистограмма позволяет исследователю "на глаз" оценить нормальность эмпирического распределения. На гистограмму также можно накладывать кривую нормального распределения.

Рис. 2.3. Пример гистограммы с наложенной кривой нормального распределения (бимодальное распределение)
Гистограмма позволяет качественно оценить различные характеристики распределения. Например, на ней можно увидеть, что распределение бимодально, т.е. имеет 2 пика. Это может быть вызвано тем, что выборка неоднородна, поэтому исследователь может попытаться найти качественный способ разделения выборки на две части.
При проверке статистических гипотез для оценки вида распределения исследователь может использовать также "ящичковые диаграммы" (box-and whisker plot). Они дают общее представление о распределении переменной: высота ящика - разброс значений, черта внутри ящика - медиана или 50%-ный процентиль, нижняя грань - 25%-ный процентиль, верхняя - 75%-ный процентиль (рис. 2.4) . Экстремальные значения, не попавшие внутрь, изображаются вне ящика, и их можно исследовать отдельно.
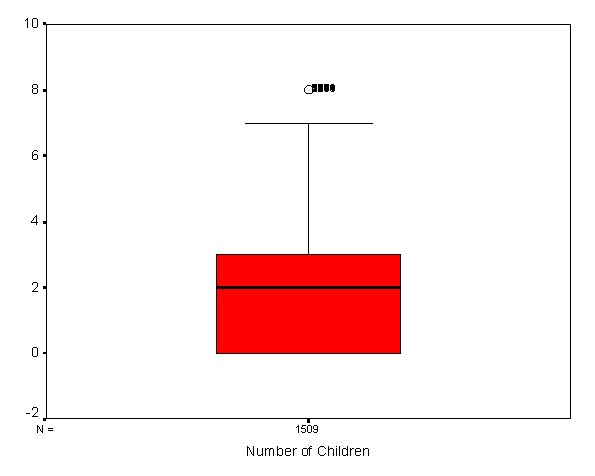
Рис. 2.4. Пример диаграммы box-and-whisker plot
Для исследования нормальности распределения можно также использовать такой метод проверки статистических гипотез, как построение графиков на нормальной вероятностной бумаге. На графике выводятся координаты фактических значений переменных (рис. 2.5., квадратики) и теоретические значения, вычисленные при условии нормальности распределения (прямая линия). Чем ближе фактические значения к этой прямой, тем более нормальным является распределение. Одновременно можно рассчитать значения критериев Колмогорова-Смирнова и Шапиро-Уилкса, основанных на нулевой гипотезе о нормальном распределении генеральной совокупности (нулевая гипотеза принимается если уровень значимости Sig. > 0,05):
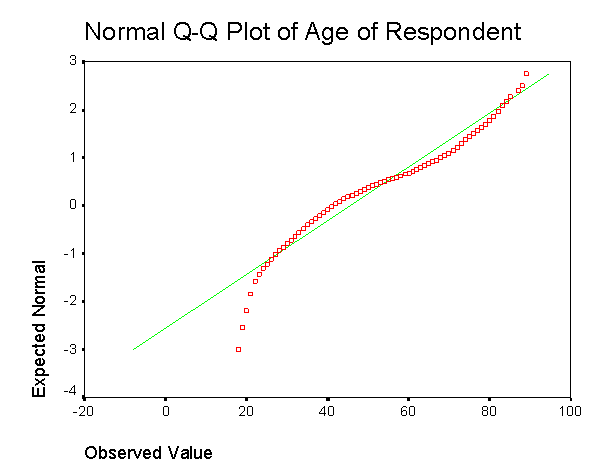

Рис. 2.5. Пример графика на нормальной вероятностной бумаге
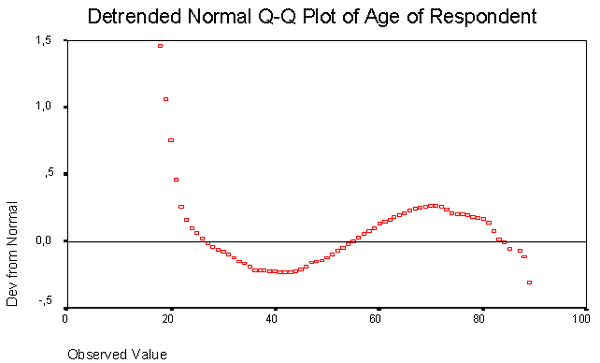
Аналогично интерпретируется график на нормальной вероятностной бумаге с удаленным трендом (рис. 2.6).
Рис. 2.6. Пример графика на нормальной вероятностной бумаге с удаленным трендом.
На графике выводятся координаты фактических значений переменных (квадратики) и теоретические значения, вычисленные при условии нормальности распределения (горизонтальная прямая). Чем ближе фактические значения к горизонтальной прямой, тем более нормальным является распределение.
Существует большое количество методов проверки нормальности распределения, но ни один из них не является универсальным. Одни методы могут подтверждать статистическую гипотезу о нормальности распределения, другие - отвергать эту гипотезу. Поэтому на практике исследователи стараются использовать несколько методов, чтобы получить как можно менее противоречивые результаты.
К методам описательной статистики относится также построение частотных таблиц. Таблицы частот или одновходовые таблицы представляют собой простейший метод анализа категориальных (номинальных) переменных. Часто их используют как одну из процедур разведочного анализа, чтобы просмотреть, каким образом различные группы данных распределены в выборке.
Например, если в опросном листе, предназначенном для выявления покупательских предпочтений, встречается вопрос о количестве детей у респондента, то из частотной таблицы (рис. 2.7) исследователь может выяснить, что 419 опрошенных или 27,6% не имеют детей, 255 (16,8%) имеют одного ребенка и т.д. Кроме того, в таблице приводятся такие показатели, как значимый процент (данные с учетом тех опросных листов, где на этот вопрос даны ошибочные ответы, которые исследователь не может интерпретировать и помечает при проведении расчетов как так называемые "пропущенные" значения), а также кумулятивный (накопленный) процент.
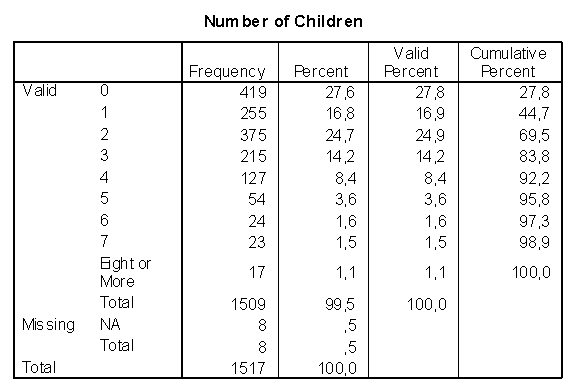
Рис. 2.7. Пример частотной таблицы.
Этот же результат для удобства интерпретации исследователь может представить в виде столбиковой диаграммы (рис. 2.8)
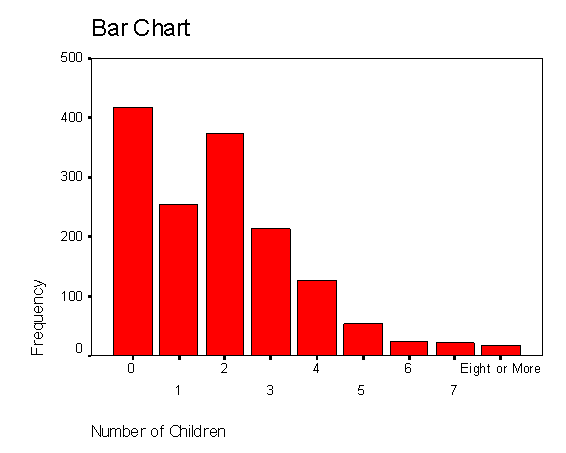
Рис. 2.8. Столбиковая диаграмма к таблице рис. 2.7.
К данным описательной статистики относятся частоты, проценты, кумулятивный процент (таблица на рис. 2.7.), а также среднее значение, мода, медиана, сумма, стандартное отклонение, минимальное и максимальное значения переменных, а также уже упоминавшиеся выше параметры, характеризующие вид распределения - асимметрия (Skewness) и эксцесс (Kurtosis) (рис. 2.9).

Рис. 2.9. Статистики к примеру
На практике каждое исследование как правило начинается с построения таблиц частот и расчета основных статистик. Например, при обработке опросных листов таблицы частот могут отображать число мужчин и женщин, выразивших положительное отношение к тому или иному товару, число респондентов из определенных регионов, которые хорошо знают ту или иную компанию и т.д. Ответы, измеренные в определенной шкале также можно свести в таблицу частот. Обычно, если в данных имеются группирующие переменные, то для них всегда вычисляются таблицы частот.
2.4. Корреляция. Исследование комбинаций непрерывных переменных.
Вычисление корреляционных функций требуется при исследовании зависимости между переменными - коэффициент корреляция и является мерой такой зависимости. Наиболее известной является корреляция Пирсона. При вычислении корреляции Пирсона предполагается, что переменные измерены, как минимум, в интервальной шкале. В случае, если используются менее информативные шкалы, применяют другие коэффициенты корреляции, как, например, коэффициент корреляции Спирмена. Коэффициенты корреляции изменяются в пределах от -1.00 до +1.00. Значение -1.00 означает, что переменные имеют строгую отрицательную корреляцию, значение +1.00 означает, соответственно, что переменные имеют строгую положительную корреляцию. Значение коэффициента, равное нулю, означает отсутствие корреляции (т.е. означает, что зависимость установить не удается, а вовсе не отсутствие зависимости!).
Наиболее часто используемый коэффициент корреляции Пирсона r называется также линейной корреляцией, т.к. измеряет степень линейных связей между переменными (рис.2.11). Корреляция Пирсона определяет степень, с которой значения двух переменных "пропорциональны" друг другу. Важно, что значение коэффициента корреляции не зависит от масштаба измерения. Например, корреляция между ростом и весом будет одной и той же, независимо от того, проводились измерения в дюймах и футах или в сантиметрах и килограммах.
Пропорциональность означает просто линейную зависимость. Корреляция высокая, если на графике, называемом диаграммой рассеяния зависимость можно представить прямой линией с положительным или отрицательным углом наклона (рис. 2.10). Эта прямая называется прямой регрессии или прямой, построенной методом наименьших квадратов. Последний термин связан с тем, что сумма квадратов расстояний от наблюдаемых точек до прямой является минимальной.
Чтобы оценить зависимость между переменными, нужно знать как величину коэффициента корреляции, так и его значимость.
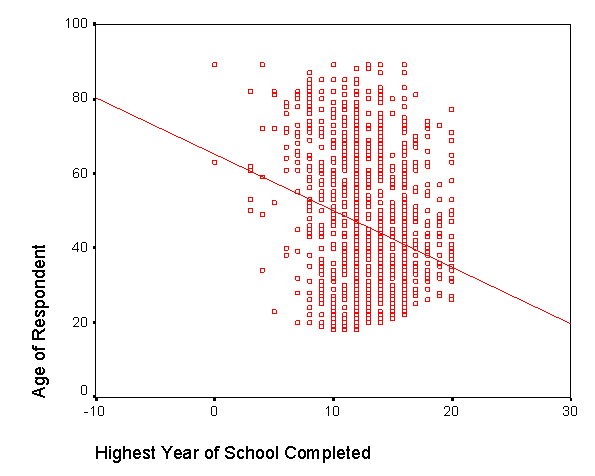
Рис. 2.10. Пример диаграммы рассеяния с наложенной линией наименьших квадратов
Уровень значимости, вычисленный для каждой корреляции, (рис.2.11), представляет собой главный источник информации о надежности полученных результатов (как правило, используется 5%-ный уровень значимости). Как уже упоминалось выше, значимость определенного коэффициента корреляции зависит от объема выборки. Критерий значимости основывается на предположении, что распределение отклонений наблюдений от регрессионной прямой для зависимой переменной является нормальным (с постоянной дисперсией для всех значений независимой переменной). Из практики применения коэффициента корреляции Пирсона известно, что нарушение этих условий не является абсолютно критичным, если размеры выборки не слишком малы, а отклонения от нормальности не очень большие.

Рис 2.11. Вычисление коэффициента корреляции Пирсона
Тем не менее, имеется несколько важных моментов, которые необходимо кратко рассмотреть.
1. Выбросы, т.е. нетипичные, резко выделяющиеся наблюдения. Так как при построении прямой регрессии используется сумма квадратов расстояний наблюдаемых точек до прямой, то выбросы могут существенно повлиять на наклон прямой и, следовательно, на значение коэффициента корреляции. Поэтому единичный выброс (значение которого возводится в квадрат) способен существенно изменить наклон прямой и, следовательно, значение корреляции. Самый простой выход заключается в исключении подобных данных. Но, возможно, эти исключенные данные являются не выбросами, а экстремальными значениями, и их наоборот, следует обязательно учитывать. В математической статистике не существует общепринятых методов удаления выбросов. Иногда применяют численные методы: например, исключаются значения, которые выходят за границы ±2 стандартных отклонений (и даже ±1.5 стандартных отклонений) вокруг выборочного среднего. К сожалению, вопрос определения выбросов является субъективным, и решение должно приниматься индивидуально в каждом конкретном случае (например, с учетом "сложившейся практики" в данной области).
2. Отсутствие однородности в выборке также является фактором, смещающим выборочную корреляцию. Высокая корреляция может быть следствием, например, разбиения данных на две группы, а вовсе не отражать зависимость между двумя переменными (зависимость может вообще практически отсутствовать).
Другим возможным источником трудностей, связанным с линейной корреляцией Пирсона, является форма зависимости. Корреляция Пирсона хорошо подходит для описания линейной зависимости. Отклонения от линейности увеличивают общую сумму квадратов расстояний от регрессионной прямой, даже если она представляет "истинные" и очень тесные связи между переменными. Например, график на рис 2.12 показывает корреляцию между двумя переменными, которую можно хорошо описать с помощью кубической функции. Такой случай, когда имеется сильная корреляция при явно нелинейной зависимости, представляет для исследователя определенные трудности. Дело в том, что не имеется естественного обобщения коэффициента корреляции Пирсона на случай нелинейных зависимостей. Исследователю приходится либо использовать логарифмическое преобразование переменных для приведения зависимости к линейной (требуется выполнение условия монотонности кривой), либо использовать более "слабые" критерии непараметрической корреляции, как, например, коэффициент корреляции Спирмена. Не существует простых методов исследования нелинейных зависимостей - существующие методы требуют наличия у исследователя большого практического опыта и навыка работы с подобными данными.
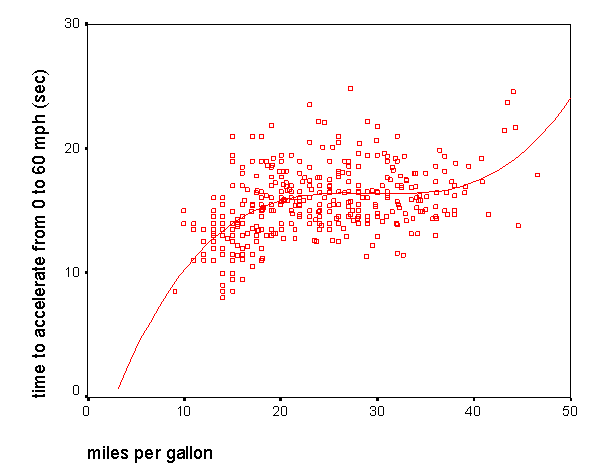
Рис. 2.12. Пример корреляционной зависимости между переменными, которую можно описать с помощью кубической функции.
При вычислении корреляционных функций важно помнить, что основываясь на коэффициентах корреляции невозможно строго доказать наличие причинной взаимозависимости между переменными. Известный "классический" пример: по результатам наблюдений в белорусской деревне вычислена сильная корреляция между увеличением количества аистов и повышением рождаемости - но из этого вовсе не следует, что детей приносят аисты. Это типичный пример так называемой ложной корреляции, т.е. корреляции, которая обусловлена влияниями других переменных, остающихся вне поля зрения исследователя. В данном случае, например, имеется третья переменная (хорошие экологические условия), которая влияет как увеличение количества аистов, так и на число рождающихся детей.
2.5. Таблицы сопряженности.
Построение таблиц сопряженности (Crosstabs) позволяет оценить взаимосвязи данных в двумерных или многомерных таблицах. Каждая ячейка таблицы сопряженности содержит информацию о количестве объектов, попадающих в группу, определенную комбинацией двух значений.
Применительно к обработке опросных листов, если выбрать строку, столбец и слой (задаваемый значением управляющей переменной), то для каждого слоя в таблице сопряженности рассчитываются соответствующие статистики. Например, если в качестве управляющей переменной используется ПОЛ (sex), то при анализе таблицы сопряженности для переменных ОТНОШЕНИЕ К ЖИЗНИ (life) и РАСА (race of respondent), результаты двумерной таблицы для женщин будут вычисляться отдельно для результатов для мужчин (рис.2.13).
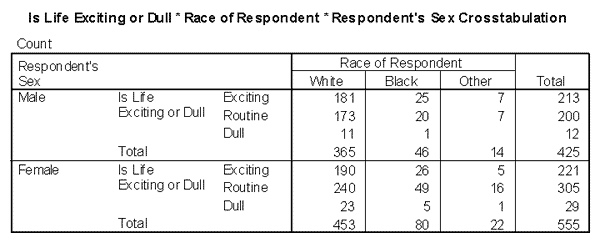
Рис. 2.13. Пример таблицы сопряженности
Например, насколько важна самооценка для мужчин и для женщин? Используя результаты маркетингового исследования (опроса), можно рассчитать соответствующую таблицу сопряженности. Из этой таблицы исследователь сможет узнать, например, что очень важна самооценка для 193 (19,7%) опрошенных мужчин и для 317 (32,3%) опрошенных женщин или для 510 (51,9%) опрошенных респондентов (рис. 2.14).
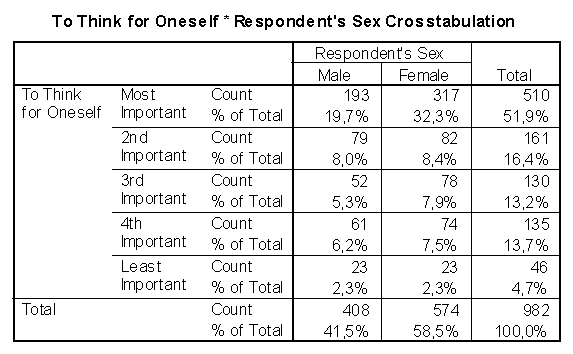
Рис. 2.14. Таблица сопряженности САМООЦЕНКА х ПОЛ
Важно заметить, что соотношения, полученные в таблицах сопряженности, применимы только к выборке. Возможность распространить полученные результаты на всю генеральную совокупность (всех потребителей), необходимо проверять с помощью статистических критериев. В математической статистике существует 22 различных критерия, здесь рассмотрим только наиболее известные.
Наиболее часто используемыми в данном случае являются критерий хи-квадрат Пирсона, отношение правдоподобия, критерий линейно-линейной зависимости. В таблице на рис. 2.15 приведены результаты вычисленные значения этих критериев для данных из таблицы на рис. 2.14:
Pearson Chi-Square - критерий хи-квадрат Пирсона;
Likelihood Ratio - отношение правдоподобия. Рассчитывается по более сложной формуле, чем хи-квадрат Пирсона (хи-квадрат представляет собой приблизительную оценку отношения правдоподобия);
Linear-by-Linear Association - критерий линейной зависимости. Представляет собой коэффициент корреляции и применим только если обе переменные - порядковые.

Рис. 2.15. Таблица значений статистических критериев
Примененные статистические критерии показывают, выполняется ли нулевая гипотеза, утверждающая, что между переменными в генеральной совокупности нет никакой зависимости. Важным показателем является ассимптотический уровень значимости (Asymp.Sig 2-sided в таблице на рис. 2.11) - обычно нулевая гипотеза отвергается, если уровень значимости меньше 5% (0,05).
2.6. Сравнение средних значений переменной в двух группах наблюдений с помощью t-критерия.
t-критерий является наиболее часто используемым методом обнаружения различия между средними двух выборок. Этот критерий следует применять для сравнения средних значений одной переменной в двух группах наблюдений.
Теоретически, t-критерий может применяться, даже если размеры выборок очень небольшие (10 или даже меньшего размера), и если переменные нормально распределены (внутри групп), а дисперсии наблюдений в группах не слишком различны. Предположение о нормальности можно проверить, исследуя распределение (например, визуально с помощью гистограммы) или применяя какой-либо критерий нормальности из рассмотренных выше. Равенство дисперсий в двух группах можно проверить с помощью критерия Ливиня. Если условия применимости t-критерия не выполнены, используют непараметрические альтернативы t-критерия.
Уровень значимости t-критерия равен вероятности ошибочно отвергнуть гипотезу о равенстве средних двух выборок, когда в действительности эта гипотеза имеет место. Иными словами, он равен вероятности ошибки принять гипотезу о неравенстве средних, когда в действительности средние равны.
Чтобы применить t-критерий для независимых выборок, требуется, по крайней мере, одна независимая (группирующая) переменная (например, ВОЗРАСТ: до 40 лет и свыше 40 лет) и одна зависимая переменная (тестовое значение некоторого показателя например ПРОБЛЕМЫ С АЛКОГОЛЕМ). В соответствии со значениями независимой переменной данные разбиваются на две группы( рис 2.12). Можно произвести анализ этих данных с помощью t-критерия, сравнивающего среднее значение переменной ПРОБЛЕМЫ С АЛКОГОЛЕМ (Drinking Problem) для двух групп респондентов: в возрасте до 40 лет, и в возрасте свыше 40 лет. каждый респондент в соответствии с возрастом попадает только в одну группу.
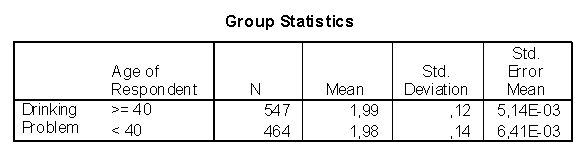

Рис. 2.15. Результаты исследования с помощью t-критерия.
Для каждого значения группирующей переменной получены: объем выборки, среднее, стандартное отклонение и стандартная ошибка среднего. Как видно из первой таблицы на рис. 2.15, хотя средние значения близки, но требуется проверить нулевую гипотезу о равенстве средних в генеральной совокупности на основе данных, полученных по выборке. Эти результаты могут быть получены с помощью t-критерия (вторая таблица на рис. 2.15):
Levene's Test for Equality of Variances - критерий равенства дисперсий Ливиня,
F - значение критерия,
Sig. - уровень значимости.
Если уровень значимости меньше 0,05, то нулевая гипотеза о равенстве дисперсий должна быть отвергнута. В этом случае для интерпретации результатов можно использовать только вторую строку таблицы.
t-test for Equality of Means - t-критерии с объединенными и раздельными дисперсиями.
t - значение t-критерия. Оно показывает направление и степень межгруппового различия средних в выборках.
Sig. (2-tailed) - уровень значимости t-критерия. Если уровень значимости меньше 0,05, то нулевая гипотеза о равенстве средних в группах должна быть отвергнута.
Анализ данных с помощью t-критерия, сравнения средних и меры отклонения от среднего в группах можно производить визуально с помощью ящичковых диаграмм (рис. 2.16). Эти графики позволяют исследователю визуально оценить степень различия средних значений в нескольких группах наблюдений.
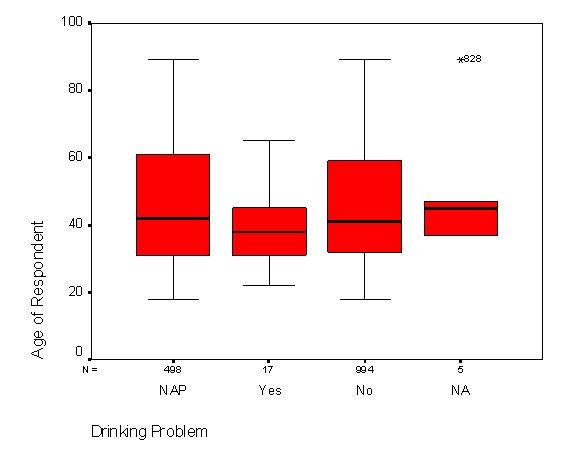
Рис. 2.16. Диаграммы box-and-whisker.
Данные выборок могут и не удовлетворять требованиям по применению t-критерия - например, когда невозможно установить равенство групповых дисперсий. В этом случае используются непараметрические критерии, в частности, критерий Манна-Уитни (U). Значение критерия вычисляется путем ранжирования подгрупп ,при этом нулевая гипотеза формулируется следующим образом: суммы рангов в обеих группах должны быть равными. Рассчитываемый уровень вероятности показывает вероятность выполнения этой гипотезы. Непараметрические критерии и, в частности, критерий Манна-Уитни, являются менее мощными, чем t-критерий, поскольку они используют меньше информации о данных; тем не менее, эти критерии часто используются в тех случаях, когда нет уверенности в том, что данные соответствуют условиям t-критерия.
2.7. Регрессионный анализ.
Линейный регрессионный анализ позволяет оценить коэффициенты линейного уравнения, содержащего одну или несколько (множественная регрессия) независимых переменных, значения которых используются для предсказания значения зависимой переменной. Вычислив коэффициенты такого уравнения, исследователь может получать предсказание значений зависимой переменной.
Регрессионный анализ является достаточно сложной статистической процедурой, поэтому ограничимся рассмотрением случая одной зависимой и одной независимой переменной и, соответственно, использования простой линейной регрессии.
Например, исследователь хочет предсказать, как будет изменяться уровень образования у респондентов при повышении уровня образования их родителей (предположим, предпринимателя интересует прогноз сбыта товаров для высокообразованных интеллектуалов).
При проведении исследования прежде всего необходимо, используя результаты опроса, получить двумерные диаграммы рассеяния для изучаемых данных. Диаграммы рассеяния помогают визуально изучить данные и предположить наличие (отсутствие) линейной взаимосвязи (рис. 2.17).
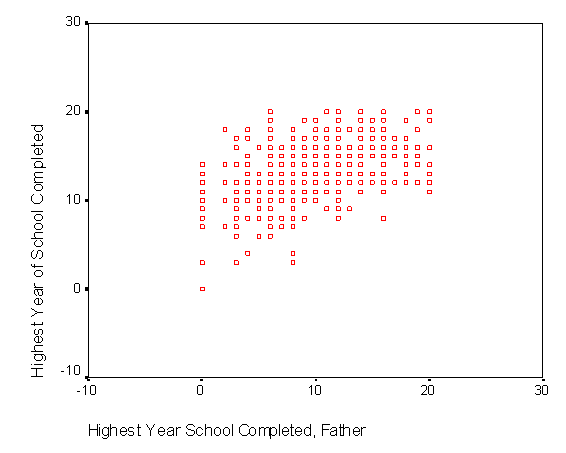
Рис. 2.17. Диаграмма рассеяния для двух переменных:
КОЛИЧЕСТВО ЛЕТ ОБУЧЕНИЯ,
КОЛИЧЕСТВО ЛЕТ ОБУЧЕНИЯ ОТЦА
Необходимо также использовать критерии нормальности (гистограмма на рис. 2.18 и график на нормальной вероятностной бумаге на рис. 2.19) для проверки нормальности распределения.

Рис. 2.18. Проверка нормальности распределения.
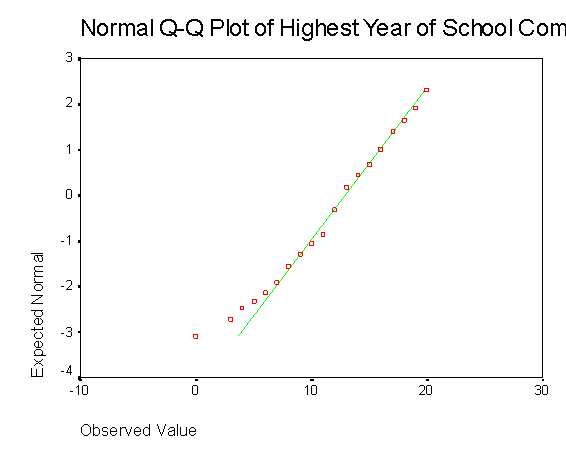
Рис. 2.19. Проверка нормальности распределения.
По предварительным результатам можно предположить, что между уровнем образования отца (числом лет обучения) и самого респондента существует линейная зависимость. С помощью линейной регрессии исследователь может построить модель взаимосвязи этих переменных (рис. 2.19).
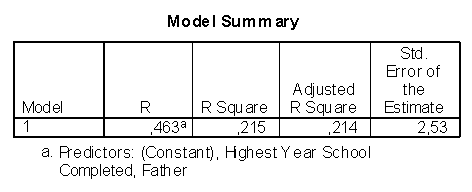
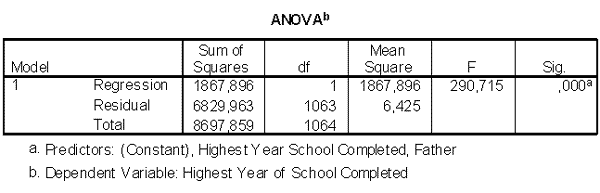
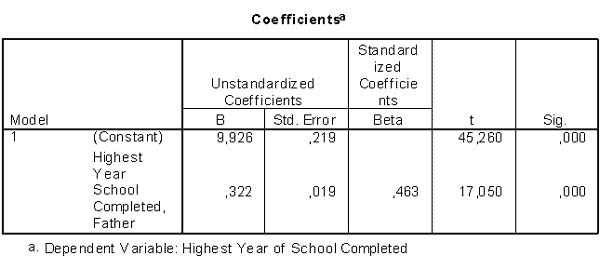
Рис. 2.20. Результаты построения модели линейной регрессии.
В результате исследования получены следующие основные результаты:
- в таблице Model Summary приводится расчетная информация, показывающая насколько хорошо значение независимой переменной может быть представлено на основе зависимой: R - коэффициент корреляции между переменными, R-square - квадрат коэффициента корреляции, показывающий, какая часть изменчивости зависимой переменной может быть объяснена независимой переменной;
- важным показателем является уровень значимости коэффициентов Sig. в таблице ANOVA. Линейная модель зависимости может считаться надежной, если уровень значимости не превышает 0,05 (5%);
- в таблице Coefficients приведены рассчитанные коэффициенты регрессионной модели. Поскольку модель является линейной, ее графическим выражением будет являться прямая
y = k * x + B, где
x - независимая переменная (в приведенном примере это уровень образования отца);
y - зависимая переменная (уровень образования респондента);
k - тангенс угла наклона (регрессионный коэффициент);
B - постоянная прямой.
Из таблицы Coefficients получаем:
значение в первой строке (постоянная В) - 9,926;
значение коэффициента (k) - 0, 322,
и, таким образом, имеем линейную регрессионную модель
y = 0,322 *x + 9,926.
Полученная модель может быть использована для предсказания уровня образования респондентов при изменении уровня образования их родителей (в приведенном примере - отцов).
Рассчитанный уровень значимости Sig. в таблице Coefficients позволяет оценить, насколько значимым является каждый из коэффициентов регрессии. На практике, как правило, принимается уровень значимости, равный 0,05 (5%), и значимыми считаются только те коэффициенты, уровень значимости которых не превышает этого значения.
В настоящей главе кратко описаны лишь некоторые наиболее известные, часто применяемые, и наиболее простые в использовании методы математической статистики. Для более углубленных исследований могут использоваться факторный и кластерный анализ, дисперсионный анализ, множественная регрессия, логлинейный анализ, методы нелинейного оценивания и прочие методы математической статистики, многие из которых (практически все известные в настоящее время!) реализованы в широко известной, мощной, постоянно развивающейся программе статистического анализа SPSS, работа с одной из версий которой (версия 8.0) будет кратко рассмотрена в следующей главе данного учебника.