Маркетинг: решение исследовательских задач
А.Л. Алифанов, Л.А.Алифанов
1. ПРОВЕРКА СТАТИСТИЧЕСКИХ ГИПОТЕЗ
1.1. Предпосылки использования в маркетинговых исследованиях статистических методов
При исследованиях показателей маркетинговой деятельности в реальных условиях во многих случаях приходится иметь дело с практически трудно управляемыми или вовсе не управляемыми, трудно изменяемыми или даже не изменяемыми исследователем факторами. Это весьма затрудняет или вовсе исключает целенаправленное варьирование их уровнями по заранее разработанному применительно к конкретной ситуации или выбранному плану, и воплощение его (даже если это принципиально возможно) может оказаться слишком дорогостоящим.
Тем не менее, если хотя бы один фактор управляем, а остальные сравнительно легко контролируемы, проводят эксперименты в разнородных условиях, сообразуясь с целью исследования и материальными возможностями.
Когда эксперименты проводятся с факторами, часть которых управляема, а другая часть неуправляема, но контролируема, то они называются активно-пассивными, если же все факторы управляемы и контролируемы – активными. Активные эксперименты предполагают отбор существенных факторов, задание границ факторного пространства, минимизацию числа опытов, построение модели, адекватной данным, и отыскание оптимума. Но уже только одно ограничение факторного пространства само по себе сильно сужает поиск и процесс формирования новых знаний, поэтому такой подход к экспериментированию в большинстве случаев, скорее, позволяет уточнить знания об объекте и упорядочить их, т. е. по сути активные эксперименты эффективны лишь на горизонтальном уровне.
Главным способом изучения маркетинговых ситуаций является наблюдение – «восприятие объекта без активного вмешательства в его поведение», хотя и «исследователь вынужден пассивно ожидать естественного проявления необходимых эффектов в поведении объекта, что значительно удлиняет ожидаемое время сбора необходимой информации» [2]. Наблюдение особенно эффективно, когда факторы трудно управляемы или неуправляемы, но контролируемы. Современные методики обработки наблюдений позволяют получать приемлемые результаты, делать достаточно точные выводы, выдвигая гипотезы и принимая или отвергая их.
Статистическая гипотеза – любое предположение о свойствах случайной величины. Выдвигаемые гипотезы подразделяются на исходную (основную), так называемую, нуль-гипотезу Н0, и конкурирующие гипотезы Н1, Н2, …Нn. Если нулевая гипотеза отвергается, то в качестве основной принимается первая из конкурирующих, если и она отвергается, то принимается вторая и т. д.
При проверке статистических гипотез используется понятие уровня значимости a. Уровень значимости (или риск производителя – в терминологии науки о контроле качества) есть вероятность ошибки первого рода – отвергнуть правильную гипотезу. Вероятность противоположного события
Рдов = 1 – a. (1.1)
Вероятность ошибки второго рода – принять неправильную гипотезу (риск потребителя) β, вероятность противоположного события 1 – β – мощность критерия. В инженерных экономических и технических расчетах уровень значимости принимают равным 0,05 или 0,1, поскольку эти значения соответствует, как правило, принятой точности измерений и объему выборок.
Можно уменьшить a – риск производителя, но тогда, вполне естественно, увеличится риск потребителя β, поэтому для уменьшения a и β необходимо увеличивать объем выборок, или увеличивать точность измерений, или увеличивать и то и другое.
Для проверки нуль-гипотезы наблюдаемое значение случайной величины сравнивают с критерием, который также является случайной величиной с известной функцией распределения. Найденные значения критерия могут находиться в критической области маловероятных значений и, напротив, в области принятия гипотез, где значения критерия допускаются с заданной доверительной вероятностью. Точки, отделяющие критическую область от области принятия гипотез, называют критическими. Правосторонняя критическая область определяется неравенством
К > Ккр,(1.2)
где К – случайная величина критерия; Ккр – значение критерия, соответствующее критической точке.
Левосторонняя критическая область имеет место, когда
К < Ккр.(1.3)
Двусторонняя критическая область отвечает неравенству
|К| > Ккр.(1.4)
Например, для нахождения правосторонней критической области задаются уровнем значимости α и определяют по соответствующим таблицам критическую точку Ккр, руководствуясь следующим соображением: при условии справедливости нулевой гипотезы вероятность того, что К > Ккр, равна a:
Р(К > Ккр) = a. (1.5)
Значит, если К находится в критической области, то нуль-гипотеза отвергается, а вероятность того, что К > Ккр, равна a – вероятности отвергнуть правильную гипотезу.
Двусторонняя критическая область, отвечающая требованиям |К| > Ккр или К < К1кр и К > К2кр при К2кр > К1кр, определяется как сумма:
Р(К < К1кр) + Р(К > К2кр) = a. (1.6)
При симметричном распределении критерия имеет место выражение
Р(К > Ккр) = a/2, (1.7)
т. е. вероятность того, что найденный критерий попадает в правостороннюю критическую область, равна a/2 (при такой же вероятности попадания в левостороннюю критическую область, что в сумме дает a).
1.2. Оценка существенности факторов, влияющих на объем производства товара, с помощью непараметрического критерия знаков
Критерий знаков является одним из самых простых способов выявления существенных факторов. Он основан на N-ста-тистике и служит для проверки гипотезы о равной вероятности положительного и отрицательного исходов для последовательности независимых событий. Результаты наблюдений (испытаний) независимы, если каждый из них не подвержен влиянию предыдущего и не содержит информации о последующем.
Если гипотеза о равной вероятности исходов независимых испытаний (их число равно n) Р{+} = Р{–} не отвергается, то нужно предположить, что исследуемый фактор, варьируемый экспериментатором, не оказывает влияния на результат испытаний. Единственное условие – отсутствие влияния других значимых факторов, кроме исследуемого.
Если количество положительных исходов равно μ, то для проверки гипотезы Н0: р = 0,5 (при конкурирующих Н1:
р < 0,5;
Н2: р > 0,5; Н3: р ≠ 0,5) по табл. 1 приложения определяют
критические значения N(a,
μ) и N(a, n – μ), соответствующие заданному уровню
значимости.
1. При альтернативе {р < 0,5} основная гипотеза отвергается с уровнем значимости a, если n ≥ N(a, μ).
2. При альтернативе {р > 0,5} основная гипотеза р = 0,5 отвергается с уровнем значимости a, если n ≥ N(a, n – μ).
3. При двусторонней альтернативе {р ≠ 0,5} основная гипотеза р = 0,5 отвергается с уровнем значимости 2a, если n ≥ N(a, min {μ, n – μ}).
Пример. По данным источника [16], приведенным в табл. 1, требуется оценить влияние географического расположения района (восток – запад) на производство фальшивых напитков li, млн дкл в 1999 г.
Таблица 1
Производство
напитков в РФ по районам, млн дкл (значения округлены)
|
1. Центральные, южные и западные районы РФ |
Σ |
||||||
|
Калинин-градская область |
Волго-Вятский |
Централь-ный |
Центрально-Черно-земн. |
Северо-Кавказск. |
Поволжский |
||
|
2,0 |
6,0 |
26,0 |
3,4 |
7,8 |
12,4 |
57,6 |
|
|
2. Северные и восточные районы РФ |
|||||||
|
Уральск. |
Западно-сибирск. |
Восточ.-сибирск. |
Дальневосточный |
Северный |
Северо- западн. |
Σ |
|
|
13,6 |
9,7 |
4,9 |
6,5 |
3,4 |
1,4 |
39,5 |
|
Решение. Чтобы можно было воспользоваться рассматриваемым критерием, область возможных значений производства напитков R по обеим группам районов делится на две равные части:
R1 = R2 = R/2 = (lmax – lmin)/2,(1.8)
R/2 = (26 – 1,4)/2 = 12,3 млн дкл,
где R1 – область положительных значений производства напитков; R2 – область отрицательных значений, lmax – значение максимального объема производства (Центральный район), lmin – значение минимального объема производства (Северо-западный район).
Количество положительных исходов для
первой группы (больших граничного значения 12,3) равно 2
(Центральный и Поволжский районы); для второй группы районов количество положительных
исходов равно 1 (Уральский
район). Поэтому
μ = 2 + 1 = 3 и при a = 0,1
по табл. 1 приложения N(0,1; 3) = 12. Поскольку число районов также равно n = 12 и, значит, n = N(0,1;
3), то гипотеза (имеется в виду
двусторонняя альтернатива) о независимости от географического расположения
района объема производства фальшивых напитков отвергается. Скорее всего, место
расположения района (в смысле принадлежности его к первой или второй группе)
все-таки влияет на объем производства фальшивой продукции.
Если же повторить процедуру отдельно для каждой группы районов, то окажется, что внутри групп расположение района не оказывает влияния на объем производства. Например, для первой группы области положительных r1 и r2 отрицательных значений равны:
r1 = r2 = r/2 = (l1max – l1min)/2; r/2 = (26 – 2)/2 = 12 млн дкл.
Количество положительных исходов для первой группы районов равно 2, поэтому μ = 2. При числе районов первой группы n1 = 6 и уровне значимости a = 0,1 величина n1< Nкр (0,1; 2) = 9 (табл. 4, приложения), т. е. гипотеза об отсутствии влияния на объем производства фальшивых напитков расположения района, если он находится в 1-й группе, не отвергается. Вариация же объемов производства внутри групп объясняется другими факторами.
1.3. Оценка значимости систематически действующих
факторов на результат деятельности фирм
с использованием критерия для количества серий
В случае проверки эффективности рандомизации (целью которой является исключение существенного влияния на исследуемый объект систематически действующих факторов) и отсутствия систематических ошибок при осуществлении наблюдений используют критерий для количества серий.
Пример. В табл. 2 представлены данные по числу продаж k компьютеров [15], тыс. шт., лидерами рынка Европы, Ближнего Востока и Африки за 1998 и 1999 гг. Требуется оценить влияние систематически действующих факторов (собственно года продаж, имиджа компании и т. п.) на результат деятельности фирм.
Таблица 2
Число
продаж компьютеров компаниями – лидерами рынка
|
Год продаж |
Компании |
Σ |
Σ Σ |
||||
|
Compaq |
Fujitsu-Siemens |
Dell |
IBM |
Hewlett-Packard |
|||
|
1998 |
4,8 |
2,8 |
2,1 |
2,4 |
1,8 |
13,9 |
|
|
1999 |
5,5 |
3,7 |
2,9 |
2,8 |
2,3 |
17,2 |
31,1 |
Решение. Среднее число продаж компьютеров, приходящееся на каждую компанию в год
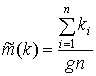 , (1.9)
, (1.9)
![]() .
.
где k – объем продаж i-й фирмой; n – число фирм; g – число лет продажи.
Считая, что данные в табл. 2 расположены в порядке их
регистрации, присваивают знак (+)
соответствующим продажам (и фирмам), которые превышают ![]() , и знак (–) продажам, меньшим, чем
, и знак (–) продажам, меньшим, чем ![]() .
.
Получаем последовательность из четырех серий: + – – – – + + – – –. Первая серия состоит из (+), вторая – из ( – – – – ), третья – из (+ +), четвертая – из (– – –). Количество минусов n = 7, количество плюсов m = 3.
Если найденное по результатам наблюдений количество серий γ удовлетворяет неравенствам
g(a; m; n) < γ < G(a; m; n), (1.10)
то гипотеза о случайном характере данных не отвергается. Если хотя бы одно из неравенств нарушится, то гипотезу следует отвергнуть. Здесь g(a; m; n) и G(a; m; n) – соответственно нижнее и верхнее критические значения для количества серий.
По табл. 2 приложения при уровне значимости a = 0,1 нижнее критическое значение равно 2, верхнее –8, следовательно, неравенство выполняется и можно считать, что в данной совокупности наблюдений систематически действующие факторы не влияют на количество продаж.
1.4. Анализ компьютерного рынка с позиций однородности объемов продаж лидирующими компаниями
Для проверки
гипотезы об однородности двух выборок
ξ1, ξ2, … ξn
и ξ΄1,
ξ΄2, … ξ΄m c независимыми элементами используют
критерий Вилкоксона W.
Проверяется основная гипотеза Н0, предполагающая, что обе выборки
принадлежат одной и той же совокупности:
Н0: Р{ξ < x} ≡ P{ξ′ < x} (|x| < ∞). (1.11)
Конкурирующей может быть гипотеза
Н1: Р{ξ < x}≠ P{ξ΄< x}. (1.12)
Предполагается, что объем первой выборки m не превышает объема n второй, т. е. m ≤ n, если это не так, то выборки просто перенумеровывают.
Расположив
значения выборок в одном вариационном ряду в порядке возрастания и пронумеровав
их, находят значение
W-статистики (Wнабл.) – сумму порядковых номеров для значений
первой выборки, затем по табл. 3 приложения находят значение нижней критической
точки wнижн. кр (a/2;
m; n)
при двусторонней критической области, а значение верхней критической точки
находят по формуле:
wверхн.кр = (m + n + 1)m – wнижн.кр.(1.13)
При wнижн.кр< Wнабл. < wверхн.кр нулевую гипотезу не отвергают.
Поскольку таблицы популярных изданий [1, 5] не содержат значений w – критических точек при m и n больших 25, то значение wнижн.кр вычисляется по приведенным в источнике [1] формулам.
Пример. Оценить однородность долей лидеров компьютерного рынка Европы, Ближнего Востока и Африки в 1998 и 1999 гг. [15]. Данные выборок приведены в табл. 3.
Таблица 3
Исходные
данные для расчета
однородности долей рынка в 1998 и 1999 гг.
|
Годы продаж |
Компании |
||||
|
Compaq |
Fujitsu-Siemens |
Dell |
IBM |
HewlettPackard |
|
|
1998 |
16,8 |
9,7 |
7,4 |
8,5 |
6,4 |
|
1999 |
16,6 |
11,1 |
8,8 |
8,4 |
6,8 |
Решение. Данные табл. 3 располагаются в виде вариационного ряда в порядке возрастания, им присваиваются порядковые номера:
6,4; 6,8; 7,4; 8,4; 8,5; 8,8; 9,7; 11,1; 16,6; 16,8
1 2 3 4 5 6 7 8 910
Вычисляется сумма номеров для 1998 г., она составляет:
Wнабл. = 1 + 3 + 5 + 7 + 10 = 26.
По табл. 3 приложения при уровне значимости a = 0,1, а для двусторонней критической области a/2 = 0,05 и m = n = 5, значения нижней и соответственно верхней критических точек равно соответственно:
wнижн.кр (0,05; 5; 5) = 19;wверхн.кр = (5 + 5 +1)5 – 19 = 36.
Поскольку
wнижн.кр (0,05; 5; 5) < Wнабл. (равное 26) < wверхн.кр (0,05; 5; 5),
гипотеза о принадлежности двух выборок одной генеральной совокупности не отвергается. Следовательно, маркетинговые мероприятия, проведенные в течение этих лет, не позволили фирмам существенно увеличить свое влияние на компьютерном рынке и потеснить конкурентов.
1.5. Вычисление количественной оценки статистической связи между качественными показателями деятельности фирм
Для оценки наличия и тесноты связи между двумя объектами, свойства которых описываются качественными показателями, используют метод ранжирования, присваивая показателям каждого объекта ранг от 1 до n в порядке, соответствующему ухудшению свойств, и вычисляют коэффициент ранговой корреляции.
Результат такой процедуры может найти применение в случае сравнительной оценки как деятельности фирм, так и производимой ими продукции при сопоставлении ее с более совершенной. Это позволит своевременно скорректировать план маркетинга в части повышения качества и установления оптимальной цены на товар.
Пример 1. В табл. 4 приведена оценка имиджа основных пивоваренных предприятий (ОАО «Ярпиво» и ОАО «Балтика») по девяти показателям на рынке Ярославской области по пятибалльной шкале [14]. Требуется оценить связь между показателями фирм «Ярпиво» и «Балтика», присвоив ранги соответствующим баллам (столбцы 3 и 5), с помощью выборочного коэффициента ранговой корреляции Спирмена.
Таблица 4
Сравнительная
характеристика предприятий по основным
показателям
|
Показатели (высказывания потребителей) |
ОАО «Ярпиво» |
ОАО «Балтика» |
||
|
Оценка |
Ранг (X) |
Оценка |
Ранг (Y) |
|
|
Хорошо известная компания |
4,9 |
1 |
4,9 |
1 |
|
Компания с большим будущим |
4,7 |
2 |
4,8 |
2 |
|
Компания, способная противопоставить свою продукцию конкурентам |
4,5 |
3 |
4,6 |
3 |
|
Быстрорастущая компания |
4,4 |
4 |
4,6 |
3 |
|
Компания, вызывающая доверие |
4,3 |
5 |
4,5 |
4 |
|
Компания, заботящаяся о потребителе своей продукции |
4,2 |
6 |
4,3 |
5 |
|
Компания, заботящаяся о качестве своей продукции |
4,1 |
7 |
4,3 |
5 |
|
Фирма, проводящая хорошо рекламную кампанию |
4,0 |
8 |
3,9 |
6 |
|
Компания, проводящая правильную ценовую политику |
4,0 |
8 |
3,5 |
7 |
Решение. Для вычисления коэффициента ранговой корреляции определяют разности рангов по каждому показателю:
di = xi – yi.
d1 = 1 – 1 = 0; d2 = 2 – 2 = 0; d3 = 3 – 3 = 0; d4 = 4 – 3 = 1;
d5 = 5 – 4 = 1; d6 = 6 – 5 = 1; d7 = 7 – 5 = 2; d8 = 8 – 6 = 2; d9 = 8 – 7 = 1.
Сумма квадратов разностей рангов
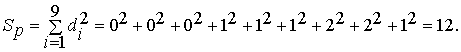
Значение коэффициента ранговой корреляции при числе объектов, равном n = 9:
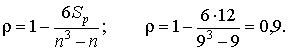
Существенность коэффициента корреляции проверяется с помощью t-критерия Стьюдента, затем исследуется гипотеза о равенстве нулю коэффициента ранговой корреляции для генеральных совокупностей Н0: ρ = 0 при конкурирующей Н1: ρ ≠ 0. При | ρ | > Tкр нулевая гипотеза отвергается. Величина критической точки вычисляется по формуле
Ткр = tкр(a; k)[(1 – ρ2)/(n – 2)]0,5, (1.14)
где a – уровень
значимости, a = 0,1; k – число
степеней свободы,
k = n – 2; n – объем
выборки.
По табл. 7 приложения для двусторонней критической области определяется значение tкр(0,1; 7) = 1,8946, тогда
Ткр = 1,8946[(1 – 0,92)/(9 – 2)]0,5 = 0,31.
Поскольку | ρ | > Ткр, нулевая гипотеза отвергается, коэффициент ранговой корреляции ρ = 0,9 значим.
Пример 2. По данным табл. 4, записанным в виде табл. 5, рангов требуется оценить связь между показателями деятельности фирм с помощью коэффициента ранговой корреляции Кендалла.
Таблица 5
Ранговые
оценки показателей деятельности ОАО «Ярпиво»
и «Балтика»
|
ОАО «Ярпиво», xi |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
8 |
|
ОАО «Балтика» yi |
1 |
2 |
3 |
3 |
4 |
5 |
5 |
6 |
7 |
Решение. Правее у1 находятся 8 рангов, больших, чем у1 (2, 3, 3, 4, 5, 5, 6, 7), поэтому R1 = 8. Правее у2 – 7 рангов (3, 3, 4, 5, 5, 6, 7), поэтому R2 = 7 и далее: R3 = 5; R4 = 5; R5 = 4; R6 = 2; R7 = 2; R8 =1. Сумма рангов R = 34.
Коэффициент ранговой корреляции Кендалла при n = 9
![]()
Значимость коэффициента τв оценивается также с помощью t-критерия. Проверяется нулевая гипотеза о равенстве нулю генерального коэффициента ранговой корреляции Н0: ρг = 0 при конкурирующей Н1: ρг ≠ 0.
Значение, соответствующее критической точке, вычисляется по формуле
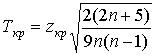 , (1.15)
, (1.15)
где zкр – критическая точка двусторонней критической области, отвечающая равенству Ф(zкр) = (1 – a)/2; n – объем выборки.
При |τв| > Ткр нулевая гипотеза отвергается.
Для вычисления Ткр вначале с помощью функции Лапласа (табл. 8 приложения) при уровне значимости a = 0,1 определяется критическая точка zкр из соотношения
Ф(zкр) = (1 – a)/2 = (1 – 0,1)/2 = 0,45, откуда zкр = 1,645, тогда
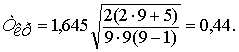
Поскольку |τв| > Ткр, нуль-гипотеза отвергается, согласно альтернативной гипотезе Н1 выборочный коэффициент ранговой корреляции Кендалла так же как и коэффициент, найденный по способу Спирмена, значим. Тот факт, что они несколько разнятся между собой, неважен, так как область возможных значений случайной величины ρ охватывает значение τв, являющегося также случайной величиной.
По результатам расчета можно сказать, что и той, и другой компании следует внимательно отнестись к пункту о проведении правильной ценовой политики, а фирме «Ярпиво» обратить внимание еще и на повышение качества своей продукции: при однородности всех остальных показателей качество продукции фирмы «Ярпиво» резко снизило коэффициент ранговой корреляции между показателями фирм. Характер других оценок показывает, что обе фирмы находятся на подъеме, но вся их деятельность направлена только на агрессивный захват рынка любой ценой, включая здоровье покупателей, и потребителю следовало бы обходить стороной их продукцию.
1.6. Оценивание резко выделяющихся показателей динамики реального денежного дохода населения
Результаты маркетинговых измерений могут содержать грубые ошибки и случайные просчеты, причем далеко не всегда представляется возможность продублировать эксперимент в тех же самых условиях и, таким образом, возникает риск потери ценной информации либо использования искаженной, привносящей недопустимую ошибку в расчеты неверной информации.
В то же время резко выделяющиеся, аномальные наблюдения могут быть абсолютно достоверными, содержащими совершенно новую, ранее не наблюдавшуюся закономерность или явление, и поэтому необходим анализ, выявление причинно-следственных связей, приведших к появлению резко выделяющегося среди других результата. Если же выяснится, что аномальное наблюдение появилось не из-за грубых ошибок или просчетов, а по причине возникновения ранее не встречавшейся ситуации, то использование вновь полученных об объекте знаний может дать в маркетинговой деятельности весьма существенный положительный эффект.
Рассмотрим наиболее часто встречающийся случай, когда параметры распределения – математическое ожидание и дисперсии – неизвестны и заменяются их оценками, определяемыми по небольшой выборке.
Результаты опытов хi располагаются в виде вариационного ряда, нулевая гипотеза, подлежащая проверке, Н0: m*(x) = xn при конкурирующей Н1: m*(x) > xmi, здесь xmi – резко выделяющееся наблюдение; m*(x) – оценка математического ожидания исследуемой величины.
Рассчитывается величина дзета-статистики по формуле
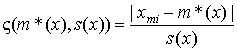 ,(1.16)
,(1.16)
где s – оценка среднего квадратического отклонения выборки.
При ς(m*(x), s(x))
< ς(n, a)
нулевую гипотезу не отвергают
(n – объем выборки).
Пример 1. Данные, приведенные в табл. 6 [12], используются для прогнозирования спроса на рынке бытовой мебели. Оценить принадлежность к выборке резко выделяющихся наблюдений.
Таблица 6
Динамика уровня реального располагаемого денежного дохода населения
(РРДД), %, в 1992–2002 гг. (за 2002 г. дан прогноз)
|
РРДД |
52,5 |
116,4 |
111,9 |
83,9 |
100,8 |
106,3 |
83,7 |
86,8 |
110,9 |
105,9 |
105,5 |
|
Год |
1992 |
1993 |
1994 |
1995 |
1996 |
1997 |
1998 |
1999 |
2000 |
2001 |
2002 |
После расположения их в виде убывающего вариационного ряда становится очевидным, что последняя цифра резко выделяется от остальных членов ряда:
116,4; 111,9; 110,9; 106,3; 105,9; 105,5; 100,8; 86,8; 83,9; 83,7; 52,5.
Требуется оценить принадлежность величины 52,5 к вариационному ряду.
Решение. Вычисляется оценка математического ожидания показателей динамики уровня РРДД:
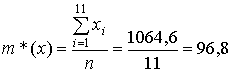 .
.
Вычисляется оценки дисперсии и среднего квадратического отклонения ряда:
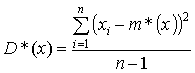 ;
;
![]() ;
D*(x) = 347,6;
s(x) = 18,6.
;
D*(x) = 347,6;
s(x) = 18,6.
После вычисления значения дзета-статистики и отыскания по табл. 4 приложения критического значения при уровне значимости a = 0,1 устанавливается, что нулевая гипотеза отвергается: значение 52,5 не принадлежит исследуемому вариационному ряду:
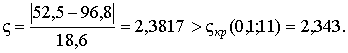
В источнике [1] приведены более простые, но несколько менее мощные критерии, статистики которых задаются отношениями:
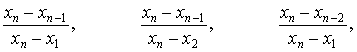 (1.17)
(1.17)
где xn, xn–1, xn–2, x2, x1 – соответственно последний, предпоследний, третий от конца, второй и первый члены вариационного ряда.
Как и в предыдущем случае, проверяется
нулевая гипотеза о принадлежности резко выделяющегося наблюдения к исследуемому
вариационному ряду Н0: xn
= xi, при конкурирующей
Н1: xn < xi.
Численные значения отношений:
![]()
При уровне значимости a = 0,1 и n = 11 критические точки (табл. 5 приложения) соответственно равны: 0,332; 0,385; 0,449. Поэтому нуль-гипотеза отвергается, следует признать, что значение 52,5 не принадлежит вариационному ряду.
Показатель динамики уровня реально располагаемого денежного дохода (РРДД) населения в 1992 г. резко отличается от показателей последующих лет. В этом смысле он не принадлежит к исследуемой генеральной совокупности потому, что управление и без того нестабильной, напрямую зависящей от международных цен на природные ресурсы экономики было подвержено в 1992 г. сильному воздействию негативных явлений. Эти явления в последующие годы стабилизировались и стали вполне нормальными, отвечающими современным, так сказать, требованиям, и неулавливаемыми для статистических критериев.
Однако при использовании информации о прошлом для прогнозирования динамики в будущие периоды показатель 1992 г. (как подтверждают сделанные расчеты) применять нельзя, если, конечно, у прогнозиста нет оснований предполагать новый всплеск провалов в управлении экономикой.
1.7. Проверка однородности выручки, получаемой от российского экспорта основных видов продукции
Для оценки однородности средних значений независимых нормально распределенных величин, дисперсии которых равны (однородны), но неизвестны, может быть использован критерий Аббе, статистика которого задается отношением
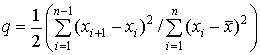 . (1.18)
. (1.18)
Проверяется нуль-гипотеза Н0: m*1(x) = m*2(x) = m*3(x) = m*4(x) при альтернативе Н1: |m*i+1 (x) – m*i (x)| > 0.
Если найденное значение q-статистики превышает критическое, то гипотеза о равенстве средних отвергается.
Пример 1. Требуется проверить гипотезу об однородности вкладов, приведенных в табл. 7, видов продукции в выручку от экспорта (данные по четырем федеральным округам РФ) в предположении, что известны только mi*(x) – средние значения выручки [17], а другой информации нет.
Таблица 7
Экспорт некоторых видов продукции России в 2000 г. по федеральным округам, млн долл
|
Федеральные округа |
Нефтехимические товары |
Черные и цветные металлы |
Машиностроительная продукция |
Древесина и изделия из нее |
|
Северо-западный |
3,0 |
2,3 |
1,5 |
1,6 |
|
Южный |
1,6 |
0,6 |
0,4 |
0,0 |
|
Сибирский |
2,3 |
5,7 |
0,5 |
1,0 |
|
Дальневосточный |
1,0 |
0,3 |
0,6 |
0,5 |
|
m*i (x) |
1,98 |
2,23 |
0,75 |
0,78 |
|
D*i (x) |
0,7 |
6,1 |
0,3 |
0,5 |
Значения средних представляют в виде вариационного ряда: 0,75; 0,78; 1,98; 2,23, со средним 1,43 и вычисляют q-статистику:
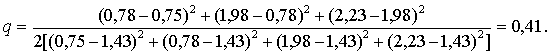
В
соответствии с табл. 6 приложения значение q-статистики при n = 4 уровне значимости α = 0,05
составляет qкр = 0,3902 < q =
= 0,41, поэтому гипотеза о
равенстве средних отвергается.
Следовательно, вклад в экспортную выручку различных видов продукции по указанным районам неодинаков: на первом месте – нефтехимические товары, на втором – черные и цветные металлы, и так далее.
Однако при вычислении q-статистики Аббе используется не вся информация об объектах, поэтому для парного сравнения средних используют критерий Стьюдента (табл. 7 приложения), тогда его статистика:
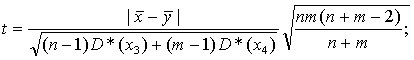 (1.19)
(1.19)
где ![]() – исследуемые средние значения; D*(x3), D*(x4) – оценки дисперсий случайных величин; n, m – объемы выборок; (n – 1),
– исследуемые средние значения; D*(x3), D*(x4) – оценки дисперсий случайных величин; n, m – объемы выборок; (n – 1),
(m – 1) – числа степеней свободы оценок дисперсий.
Проверяется нулевая гипотеза Н0: ![]() при альтернативной Н1:
при альтернативной Н1:
![]() при условии однородности оценок
дисперсий и нормального распределения X и Y. Нулевая гипотеза отвергается, если |tнабл.| > tдвуст.кр
(α/2; k), где a – уровень
значимости, k –
число степеней свободы, k = n + m – 2.
при условии однородности оценок
дисперсий и нормального распределения X и Y. Нулевая гипотеза отвергается, если |tнабл.| > tдвуст.кр
(α/2; k), где a – уровень
значимости, k –
число степеней свободы, k = n + m – 2.
Пример 2. Оценить с помощью t-критерия однородность средних значений экспортной выручки для трех вариантов:
1) от машиностроительной продукции и древесины и изделий из нее при выполнении условия однородности оценок D*(x3) и D*(x4);
2) от нефтехимических товаров, черных и цветных металлов;
3) от нефтехимических товаров и древесины и изделий из нее.
Решение. 1. В соответствии с формулой
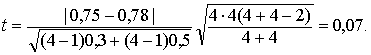
Найденное значение t-статистики меньше критического (табл. 7, приложения);
tнабл.= 0,07 < tдвуст.кр (0,1/2; 6) = 1,9432,
поэтому гипотеза о равенстве выручки по четырем районам РФ от машиностроительной продукции и от древесины и изделий из нее не отвергается.
2. Прежде, чем вычислить значение t-статистики для второго варианта, необходимо проверить однородность оценок дисперсий c помощью F-статистики (табл. 10 приложения):
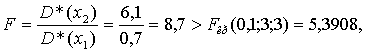
т. е. оценки дисперсий для исследуемых товаров X1 и X2 неоднородны, t-критерий не позволяет решать задачу об однородности m*(x1) и m*(x2).
3. Здесь очевидно, что оценки дисперсий однородны, значение t-статистики
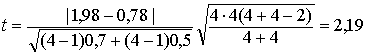 ,
,
поскольку tнабл. = 2,19 > tдвуст.кр (0,1/2; 6) = 1,9432 (табл. 7 приложения). Средние значения товаров X1 и X4 неоднородны, экспортная выручка от товаров нефтехимии больше, чем от древесины и изделий из нее. Все это согласуется с результатом, полученным при использовании критерия Аббе, который дает положительный ответ по поводу однородности средних значений только в случае, когда все средние однородны, но, если хотя бы одно значение неоднородно с каким–либо другим, то и ответ будет отрицательным.
Однородность средних
для зависимых выборок проверяется с помощью d-статистики.
Проверяется нулевая гипотеза
Н0 : М*(X)
= M*(Y) при конкурирующей Н0: М*(X)
≠ M*(Y).
Пример 3. Средний балл успеваемости группы ИЭ-00 по математике в первом семестре по результатам экзаменационной сессии составил 3,43, во втором – 3,52, в третьем – 3,65, в четвертом – 3,74. Оценить однородность средних баллов, полученных студентами группы ИЭ-00 в 1-м и 4-м семестрах по математике во время экзаменационных сессий (табл. 8).
Таблица 8
Баллы, полученные
студентами группы ИЭ-00 по математике в 1-м и 4-м
семестрах
|
Семестр |
Балл |
||||||||||||||||||||||
|
1 |
3 |
3 |
3 |
3 |
3 |
4 |
3 |
3 |
3 |
5 |
3 |
4 |
3 |
4 |
3 |
3 |
3 |
5 |
4 |
4 |
3 |
3 |
4 |
|
4 |
4 |
3 |
3 |
3 |
4 |
5 |
3 |
3 |
4 |
4 |
3 |
4 |
3 |
4 |
4 |
3 |
3 |
5 |
4 |
5 |
4 |
3 |
5 |
Решение. Выборки зависимы, так как баллы 1-го и 4-го семестров в каждом столбце получены одним и тем же студентом и в силу этого являются попарно зависимыми.
Вычисляется среднее значение разностей баллов
d* = Σdi /n,
где di = xi – yi; xi, yi – баллы студентов, полученные ими в 1-м и 4-м семестрах соответственно, n – число студентов в группе.
d1 = 3 – 4 = – 1; d2 = 3 – 3 = 0;…; d5 = 3 – 4 = – 1;
d6 = 4 – 5 = – 1;…; d9 = 3 – 4 = – 1; d10 = 5 – 4 = 1;
d15 = 3 – 4 = – 1;…; d20 = 4 – 5 = – 1; d21 = 3 – 4 = – 1;
d22 = 3 – 3 = 0; d23 = 4 – 5 = –1.
Σdi = – 1 – 1 – 1 – 1 + 1 – 1 –1 – 1 – 1 = – 7;
d* = –7 / 23 = – 0,304.
Сумма квадратов разностей
Σd2i = (–1)2 + (–1)2 +(–1)2 + (–1)2 + (+1)2 + (–1)2 +(–1)2 + (–1)2 + (–1)2 = 9.
Среднее квадратическое отклонение разностей
Sd
= 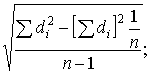 Sd =
Sd = 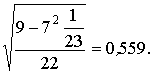
Наблюденное значение Т-статистики
Тнабл = d*n0,5/Sd = – 0,304·230,5/0,559 = – 2,6081.
Поскольку абсолютное значение Т-статистики больше, чем критическое значение tдвуст.кр.(0,10; 32) = 1,70 (табл. 7 приложения), средние баллы 1-го и 4-го семестров неоднородны, поэтому можно считать, что от 1-го к 4-му семестру имеет место небольшое, но значимое повышение успеваемости.
1.8. Оценка однородности условий маркетинговой деятельности
Все этапы маркетинга как деятельности, направленной на удовлетворение нужд и потребностей людей, от производства товаров до потребления зависят от множества факторов, в том числе от неуправляемых и неконтролируемых. Результаты наблюдений характеризуются оценками математических ожиданий и дисперсий.
Если две (или несколько) выборки исследуемой величины получены при воздействии одних и тех же и с одинаковой интенсивностью влияющих на результат факторов (т. е. в однородных условиях), то оценки их математических ожиданий и дисперсий не должны существенно отличаться (т. е. выборки будут принадлежать одной и той же генеральной совокупности). Поэтому при проверке гипотезы об однородности двух выборок вначале проверяют однородность оценок дисперсий, позволяющую предположить однородность условий проведения наблюдений, и только в случае их однородности проверяют однородность средних.
Если при проведении эксперимента варьируется один (или несколько) из числа предположительно значимых факторов и при фиксации его (или их) на заранее выбранных уровнях, которые могут иметь место в естественных условиях, регистрируются значения исследуемой величины, то оценки дисперсий в выборках должны быть однородными, поскольку условия однородности воспроизведения опытов не нарушаются. Оценки математических ожиданий выборок будут неоднородными, если фактор (или несколько варьируемых факторов) значим, и однородными, если фактор незначим.
Во всех случаях однородность условий проведения опытов предполагает однородность оценок дисперсий. Обратное утверждение (однородность дисперсий означает однородность условий проведения опытов) может быть верным, если имеются все физические предпосылки для этого.
При сравнении двух выборочных независимых дисперсий используется F критерий Фишера, при этом для проверки нулевой гипотезы Н0: D*(x1) = D*(x2) вычисляется отношение большей оценки дисперсии к меньшей. В качестве конкурирующей принимается Н1: D*(x1) > D*(x2) либо Н2: D*(x1) ≠ D*(x2), во втором случае имеет место двусторонняя критическая область.
Найденное Fнабл. сравнивается с критическим значением
(табл. 10 приложения) при заданном уровне значимости a
(a/2
при двусторонней критической области) и числах степеней свободы оценок
дисперсий f1 и f2
(число степеней свободы оценки дисперсии
равно объему наблюдений минус единица).
В случае Fнабл. < Fкр (a; f1; f2) гипотеза об однородности оценок дисперсий не отвергается.
Пример. В качестве сравнительной оценки культурного уровня населения, наличия культурных ценностей в стране существует показатель, характеризующий число посещений очагов культуры в течение года, приходящееся на 1 человека [19].
Для оценки однородности популярности различных центров культуры (табл. 9) требуется оценить однородность оценок дисперсий с помощью критерия Фишера (табл. 10 приложения).
Таблица 9
Уровень посещаемости музеев и театров за рубежом и в России на 1 января 1999 г.
|
Страна |
Посещение музеев, на 1 чел. в год |
Посещение театров, на 1 чел. в год |
|
1 |
2 |
3 |
|
Россия |
0,5 |
0,3 |
|
США |
1,3 |
1,6 |
|
Норвегия |
1,9 |
2,5 |
|
Австрия |
1,8 |
2,0 |
|
Канада |
1,7 |
2,1 |
|
Германия |
1,2 |
1,6 |
|
Италия |
– |
1,4 |
|
m*(x) |
1,4 |
1,6 |
|
D*(x) |
0,27 |
0,49 |
Решение. Критерий Фишера F вычисляется по формуле
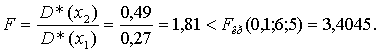
Следовательно, гипотеза об однородности оценок дисперсий не отвергается при уровне значимости α = 0,1. Сравнение средних, исключение резко выделяющихся наблюдений проводить можно. Кроме очевидного последнего места, занимаемого в настоящее время Россией можно предположить, что и музеи, и театры посещает публика одного уровня.
В тех случаях, когда требуется проверить гипотезу об однородности нескольких оценок дисперсий, вычисленных по выборкам одинакового объема, используют критерий Кокрена. Им удобно пользоваться, например, при проведении дисперсионного анализа.
Проверяется гипотеза Н0: D*1 (y) = D*2 (y) =…= D*n (y) при конкурирующей Н1: D*j (y) > D*1 (y) = D*2 (y) =…= D*i (y)=… = D*n (y).
G-статистика критерия Кокрена выражается формулой:
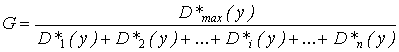 , (1.20)
, (1.20)
где D*max (y) = max(D*1 (y); D*2 (y);… D*i (y);… D*n (y)).
Если при уровне значимости α, числе степеней свободы каждой из оценок дисперсий f, равном объему каждой выборки минус единица, а также числе исследуемых оценок дисперсий n имеет место (табл. 11 приложения) выражение:
Gнабл.< Gкр.(α; f; n), (1.21)
то гипотеза об однородности оценок дисперсий не отвергается.
Пример 1. В табл. 10 приведены данные об объемах месячных продаж безалкогольного напитка «Тархун» в течение семи лет с 1993 по 1999 гг. [11]. Требуется оценить однородность оценок дисперсий ежемесячного потребления напитка, предполагающую неизменность воздействия значимых факторов на объем продаж по годам.
Таблица 10
Ежемесячное
потребление безалкогольного напитка «Тархун» в 1993–1999
гг., тыс. дкл
|
Месяц |
Год |
||||||
|
1993 |
1994 |
1995 |
1996 |
1997 |
1998 |
1999 |
|
|
Январь |
6,7 |
7,2 |
7,7 |
7,9 |
8,4 |
8,5 |
8,8 |
|
Февраль |
6,6 |
6,9 |
7,3 |
7,4 |
7,8 |
8,4 |
8,8 |
|
Март |
8,5 |
9,1 |
8,7 |
8,9 |
10,2 |
10,6 |
11,2 |
|
Апрель |
8,5 |
9,1 |
9,3 |
9,8 |
10,4 |
10,9 |
10,9 |
|
Май |
9,1 |
10,0 |
10,2 |
10,1 |
11,2 |
11,0 |
11,9 |
|
Июнь |
10,6 |
10,5 |
10,3 |
9,8 |
11,9 |
12,6 |
13,0 |
|
Июль |
10,6 |
9,8 |
11,5 |
11,4 |
12,0 |
12,6 |
12,1 |
|
Август |
10,5 |
10,4 |
11,0 |
11,9 |
11,1 |
12,0 |
12,8 |
|
Сентябрь |
9,0 |
8,9 |
9,3 |
10,5 |
10,5 |
10,9 |
11,0 |
|
Октябрь |
7,8 |
8,3 |
9,2 |
9,9 |
9,7 |
9,7 |
10,5 |
|
Ноябрь |
7,9 |
8,1 |
8,3 |
8,9 |
9,8 |
9,6 |
9,8 |
|
Декабрь |
8,1 |
8,3 |
8,3 |
9,3 |
9,6 |
9,7 |
9,4 |
|
m*(y) |
8,7 |
8,9 |
9,3 |
9,7 |
10,2 |
10,5 |
10,9 |
|
D*(y) |
1,91 |
1,38 |
1,68 |
1,68 |
1,62 |
2,01 |
2,09 |
Решение. В двух последних строках табл. 10 представлены
оценки математических ожиданий и дисперсий. Значение
G-статистики
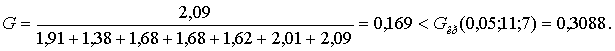
Следовательно, гипотеза об однородности оценок дисперсий не отвергается, что говорит о стабильности и однородности условий в течение семи лет, в которых осуществлялась продажа напитка. Постоянное ежегодное увеличение продаж напитка (m*(y) возрастает) свидетельствует об успешном внедрении маркетинговых мероприятий.
При оценке однородности нескольких
оценок дисперсий, найденных по выборкам неодинакового объема (число выборок
более трех) из нормально распределенных генеральных совокупностей, используют
критерий Бартлетта, основанный на
М-статистике:
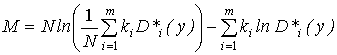 , (1.22)
, (1.22)
где 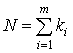 ; ki – число
степеней свободы i-й дисперсии, равное соответствующему
объему выборки минус единица; m – число
сравниваемых оценок дисперсий; D*i(y) – оценка i-й дисперсии.
; ki – число
степеней свободы i-й дисперсии, равное соответствующему
объему выборки минус единица; m – число
сравниваемых оценок дисперсий; D*i(y) – оценка i-й дисперсии.
Проверяется нулевая гипотеза Н0: D*1 (y) =…= D*i (y) = … = D*m (y) при конкурирующей Н1: D*1 (y) ≠ D*i (y). Табл. 12 приложения содержит критические значения М-статистики в зависимости от наперед заданного уровня значимости α, числа степеней свободы k = m – 1 и величин С1, С3, С, ΔС, вычисляемые по формулам
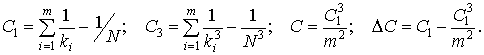 (1.23)
(1.23)
В некоторых случаях используется функция m(α), вычисляемая по формуле,
![]() (1.24)
(1.24)
Правила, применяемые при использовании М-критерия [1]:
1. Вычисляется значение М-статистики (Мнабл.);
2. Мнабл. сравнивается со значениями ma и mb в строке k табл. 12 приложения; если при всех С1 величина ma ≤ M, то гипотезу о равенстве дисперсий Н0 отвергают, если же при всех С1 имеет место М ≤ mb, то Н0 не отвергается.
3. В тех случаях, когда max ma > M ≥ min mb, вычисляют С1 и по табл. 12, приложения находят ma(α; k; C1) и mb(α; k; C1); если ma(α; k; C1) ≤ M, то Н0 отвергается; если же М < mb(α; k; C1), то Н0 не отвергается.
4. При ma(α; k; C1) > M ≥ mb(α; k; C1) вычисляется значение m(α); если m(α) ≤ M, то Н0 отвергается; если же M < m(α), то Н0 не отвергается.
Пример 2. По данным табл. 11 проверить однородность оценок дисперсий экспорта продовольственных товаров и сырья для их производств, тыс. долл [17], из субъектов Российской федерации в 2000 г.
Таблица 11
Экспорт
продовольственных товаров и сырья для
их производства из субъектов Российской Федерации в 2000 г.
|
№ п/п |
Субъект Российской Федерации |
Экспорт (тыс. долл) |
|
1 |
Субъекты РФ, экспортирующие максимум товаров |
m*1 (y)= 151,7 |
|
Москва |
152,2 |
|
|
Камчатская область |
115,0 |
|
|
Ростовская область |
187,8 |
|
|
2 |
Северо-Западный федеральный округ |
m*2 (y) = 34,9 |
|
Санкт-Петербург |
54,7 |
|
|
Калининградская область |
34,5 |
|
|
Мурманская область |
37,5 |
|
|
Новгородская область |
13,0 |
|
|
3 |
Южный федеральный округ и Самарская область |
m*3 (y) = 31,6 |
|
Краснодарский край |
65,6 |
|
|
Ставропольский край |
23,0 |
|
|
Астраханская область |
16,2 |
|
|
Московская область |
57,6 |
|
|
Волгоградская область |
16,7 |
|
|
Самарская область |
26,9 |
|
|
Белгородская область |
15,4 |
|
|
4 |
Уральский и Сибирский федеральный округ |
m*4 (y) = 31,7 |
|
Курганская область |
40,9 |
|
|
Челябинская область |
12,4 |
|
|
Алтайский край |
34,9 |
|
|
Новосибирская область |
17,0 |
|
|
Омская область |
53,3 |
|
|
5 |
Дальневосточный федеральный округ |
m*5 (y) = 49,5 |
|
Приморский край |
81,2 |
|
|
Хабаровский край |
16,3 |
|
|
Сахалинская область |
51,1 |
Решение. Вычисляя по каждому j-му округу оценки математических ожиданий и дисперсий величин экспорта, их заносят в табл. 12.
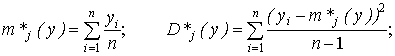
Таблица 12
Вычисление
параметров для нахождения М-статистики
|
№ п/п |
D*i (y) |
ki |
1/ki |
kiD*i (y) |
lnD*i (y) |
kilnD*i (y) |
|
1 |
1325 |
2 |
0,5 |
2650,4 |
7,1893 |
14,3786 |
|
2 |
292,9 |
3 |
0,33 |
878,6 |
5,6797 |
17,039 |
|
3 |
441,6 |
6 |
0,17 |
2649,7 |
6,0904 |
36,5425 |
|
4 |
287,5 |
4 |
0,25 |
1150,0 |
5,6612 |
22,6450 |
|
5 |
1054,8 |
2 |
0,5 |
2109,7 |
6,9611 |
13,9223 |
|
Σ |
17 |
1,75 |
9438 |
104,5274 |
М-статистика равна
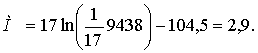
Так как при уровне значимости α = 0,05 и числе степеней свободы k =5 – 1 = 4 величина М-статистики mb(0,05; 4; C1) при любых C1 больше Мнабл. (по табл. 12 приложения минимальное значение mb(0,05; 4; 0,0) = 7,81), то гипотеза об однородности дисперсий не отвергается.
Замечание 1. Если предположить, что наблюдаемое значение М-статистики получилось равным 8,3, тогда необходимо было бы вычислить значение С1, оно было бы равно:
![]()
Используя линейную интерполяцию, по табл. 12 приложения получают mb(0,05; 4; 1,69) = 8,41. Поскольку оно превышает Мнабл., то и в этом случае гипотеза об однородности дисперсий не отвергалась бы.
2. Если предположить, что наблюдаемое значение М-статис-тики Мнабл. = 8,5, т. е. согласно табл. 12 приложения получится, что mb < Mнабл. < ma, то сначала нужно вычислить С3, С, ΔС:
![]()
![]() .
.
Далее вычисляется величина m(α):
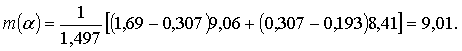
Поскольку предполагаемое Мнабл = 8,5 < m(α) = 9,01, то гипотеза об однородности дисперсий и в этом случае не отвергалась бы.
Оглавление